Does each Coding Agent use your data for model training? I read the terms
by 逆瀬川ちゃん
11 min read
Hi there! This is Sakasegawa (@gyakuse)!
I was about to pick Cursor back up after a while, but then I saw that Composer 2 is based on Kimi, and I thought, "wait, is Cursor really ZDR (Zero Data Retention)?" One thing led to another and I ended up investigating all the other Coding Agents too (?). If you're motivated to contribute your data to training, you might be surprised to find out that most of them don't actually train on it. And if you'd rather not contribute, this should help you eliminate the risk of your code being used. Kimi Code stood out: it trains on your data enthusiastically unless you email them. If you want to help push the frontier, that's a great option. For what it's worth, even the API usage of Kimi (Moonshot AI) gets used for model training. Pretty bold.
Update 2026-03-27: GitHub Copilot announced that starting April 24, data from Free/Pro/Pro+ users will be used for AI model training by default. See the GitHub Copilot section below. I also updated the rest of the tool information to reflect the latest terms.
Scope of the investigation
I read the terms of service and privacy policies of the following products.
| Tool | Developer |
|---|---|
| GitHub Copilot | GitHub (Microsoft) |
| Codex | OpenAI |
| Claude Code | Anthropic |
| Antigravity | |
| Cursor | Anysphere |
| Devin | Cognition AI |
| Kiro | Amazon (AWS) |
| WindSurf | Cognition AI |
| Kimi Code | Moonshot AI |
I'm not covering OpenCode here, but for reference, OpenCode Zen explicitly states that models like MiniMax M2.5 Free and Big Pickle are used for training. This is pretty common for free models.
Big Pickle: During the free period, collected data may be used to improve the model. MiniMax M2.5 Free: During the free period, collected data may be used to improve the model.
Results
Here's a summary.
| Tool | Used for training? | Opt-out | Data retention |
|---|---|---|---|
| GitHub Copilot | From 4/24: Free/Pro/Pro+ on by default / Business/Enterprise: not used | Free/Pro/Pro+: yes / Business/Enterprise: not needed | Zero (IDE) / retained (CLI etc., details delegated to product docs) |
| Codex | Optional | Yes | 30 days |
| Claude Code | Optional | Yes | 30 days (OFF) / 5 years (ON) |
| Antigravity | ? | ? | Retained until you request deletion |
| Cursor | Optional | Yes | Zero when Privacy Mode is ON |
| Devin | Optional | Yes | Not specified |
| Kiro | Optional | Yes | Not specified |
| WindSurf | Optional | Yes | Not specified |
| Kimi Code | Yes (used) | Yes (by email) | Not specified |
Antigravity opts you out if you access via Google Workspace or GCP. As I'll explain later, this gets a bit tricky for personal accounts. Below I'll go through each tool's opt-out method and what the terms actually say.
Each tool's terms
GitHub Copilot
How to opt out
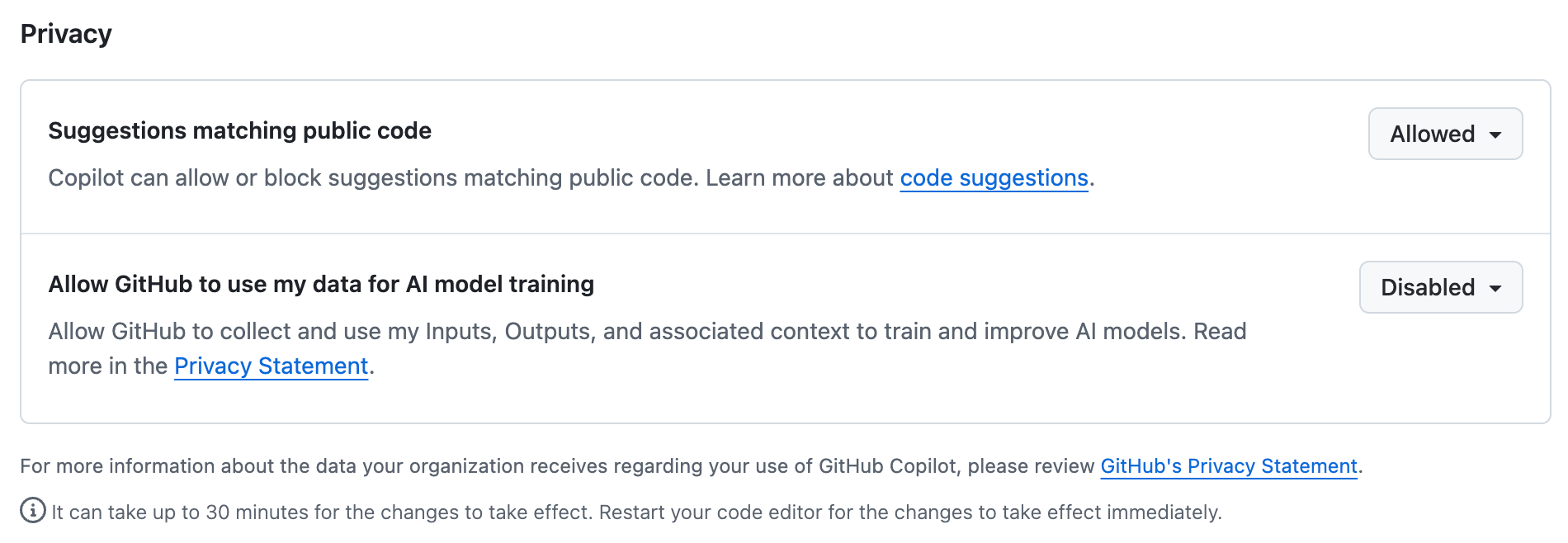
On March 25, 2026, GitHub announced revisions to its Privacy Statement and Terms of Service, taking effect on April 24. This significantly changes the landscape.
- Free/Pro/Pro+: Starting April 24, 2026, your data is used for AI model training by default
- Go to Settings > Copilot > Features and set
Allow GitHub to use my data for AI model trainingto Disabled - If you also want to refuse product-improvement usage, turn off
Allow GitHub to use my data for product improvementsas well
- Go to Settings > Copilot > Features and set
- Business/Enterprise: Not used for training (no setting needed)
Terms (announced March 25, 2026; effective April 24)
The Terms of Service revision announced on March 25 adds a new Section J (AI Features). The structure is: unless you opt out, you grant GitHub and its affiliates (including Microsoft) the right to use Inputs/Outputs for training. GitHub Docs also added this:
For Free, Pro, and Pro+ subscribers, GitHub will begin using "interactions with GitHub features and services -- including inputs, outputs, code snippets, and associated context -- to train and improve AI models" unless users opt out.
For Business/Enterprise, the GitHub Generative AI Services Terms replaced the old Product Specific Terms on March 5, 2026. Here, the no-training commitment is codified as a contractual clause.
"GitHub will not use Inputs or Outputs to train generative AI models, unless you have given us documented instructions to do so."
The Privacy Statement revision explicitly calls out AI training in the context of data sharing with affiliates (including Microsoft). It states that your opt-out setting carries over to the downstream data recipients.
As for data retention, the basic structure (immediate deletion inside the IDE, retention for out-of-IDE like CLI) is preserved, but the new Generative AI Services Terms delegates the specific retention durations from the contract itself to each product's documentation.
"Some Generative AI Services retain Inputs and Outputs to provide the service, such as maintaining functionality in stateless environments outside the code editor. Details on data retention are provided in the product documentation for each Generative AI Service."
Old terms (snapshot as of March 21, 2026, for reference)
Terms as of March 21, 2026 (click to expand)
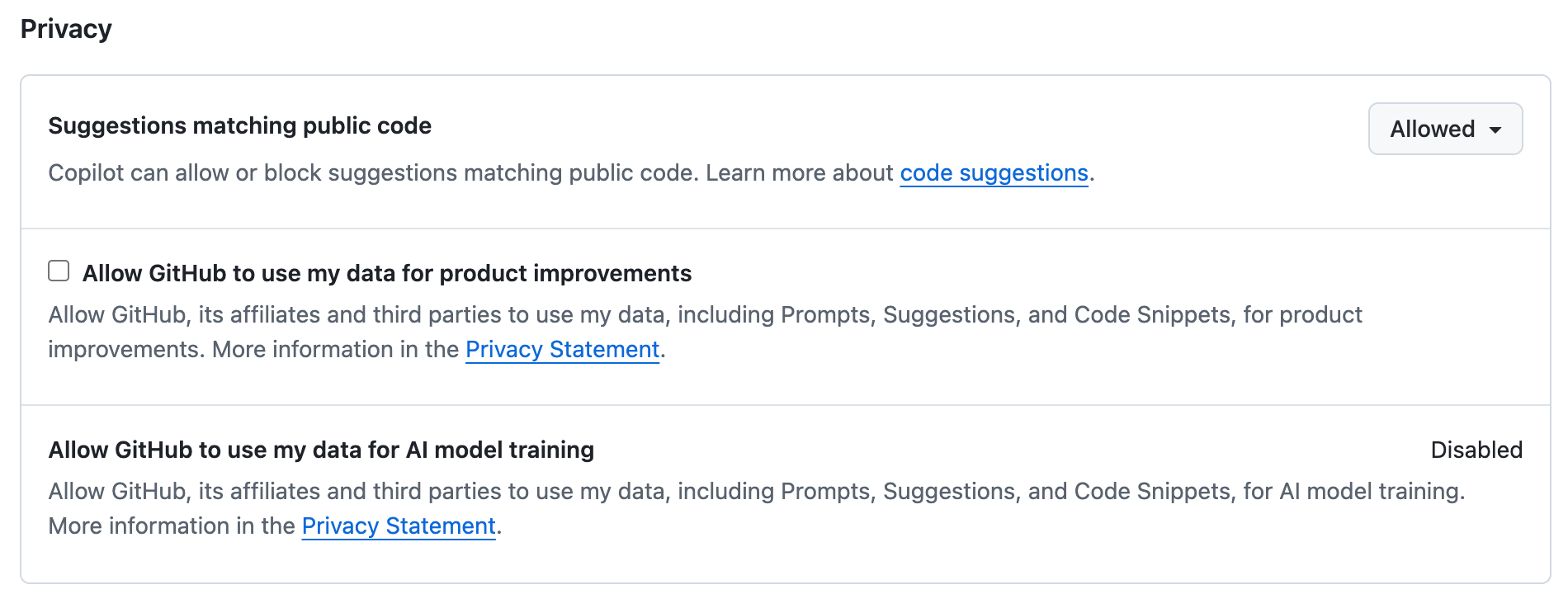
At this point, training was not used on any plan, and the opt-in setting was locked so you couldn't enable it.
The Product Specific Terms (March 2026) (for Business/Enterprise; migrated to GitHub Generative AI Services Terms on March 5, 2026) read as follows:
"GitHub Copilot sends an encrypted Prompt from you to GitHub to provide Suggestions to you. Except as detailed below, Prompts are transmitted only to generate Suggestions in real-time, are deleted once Suggestions are generated, and are not used for any other purpose."
For personal plans, GitHub Docs said:
"By default, GitHub, its affiliates, and third parties will not use your data, including prompts, suggestions, and code snippets, for AI model training. This setting cannot be enabled."
IDE usage was zero-retention, while prompts via CLI were retained for 28 days.
Codex
How to opt out

https://chatgpt.com/#settings/DataControls
- API key auth: Training usage is OFF by default
- Subscription (ChatGPT login): ChatGPT's policy applies. Change it from ChatGPT Settings > Data Controls
Terms
For API key auth, Data controls in the OpenAI platform applies.
"Your data is your data. As of March 1, 2023, data sent to the OpenAI API is not used to train or improve OpenAI models (unless you explicitly opt in to share data with us)."
Data retention is 30 days for safety monitoring purposes. The CLI is open source under Apache-2.0, so you can audit what gets sent yourself.
Claude Code
How to opt out

https://claude.ai/settings/data-privacy-controls > Turn Help improve Claude OFF
Terms
The Data Usage policy reads as follows:
"We give you the choice to allow your data to be used to improve future Claude models. We will train new models using data from Free, Pro, and Max accounts when this setting is on (including when you use Claude Code from these accounts)."
Data retention differs depending on the setting.
"Users who allow data use for model improvement: 5-year retention period to support model development and safety improvements. Users who don't allow data use for model improvement: 30-day retention period."
Antigravity
How to opt out
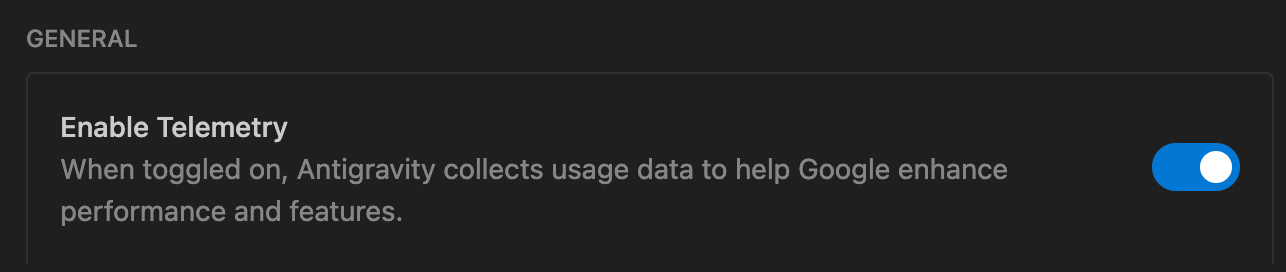
Gear icon at the top right > Open Antigravity User Settings > Turn Enable Telemetry OFF
That said, it's unclear whether this actually prevents training usage. Access via Google Workspace or GCP isn't collected, but direct login via a GCP project ID is in a limited invite-only preview, with no new signups being accepted. Realistically, individual developers don't have many privacy-preserving options.
Terms
The Terms of Service states:
"We use Interactions to evaluate, develop, and improve Google and Alphabet research, products, services and machine learning technologies."
"if you are accessing the Service via Google Workspace or the Google Cloud Platform, we will not collect your prompts, content, or model responses."
On data retention, you can read the following as "retained unless you request deletion":
"interaction data will be used according to the agreement unless and until you request deletion."
Cursor
How to opt out
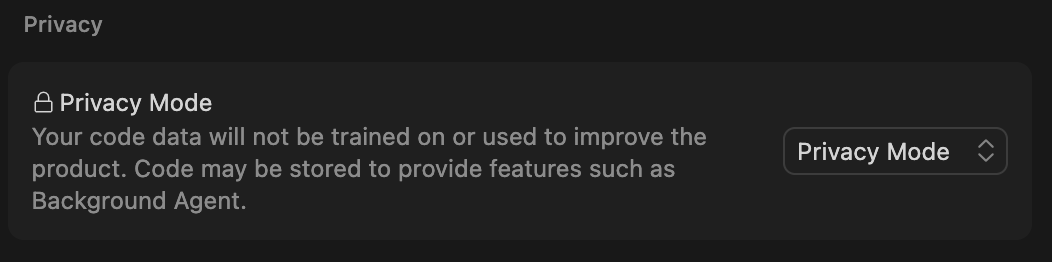
Select Privacy Mode from Settings > Privacy
- Privacy Mode: Not used for training. Features like Background Agent are still available
- Privacy Mode (Legacy): Not used for training and code is not stored. Some features (like Background Agent) are unavailable
Terms
The Data Use Overview states:
"If you choose to turn off 'Privacy Mode': we may use and store codebase data, prompts, editor actions, code snippets, and other code data and actions to improve our AI features and train our models."
Turning Privacy Mode ON enables zero data retention.
"If you enable 'Privacy Mode' in Cursor's settings: zero data retention will be enabled for our model providers. (...) None of your code will ever be trained on by us or any third-party."
One caveat: even if you set your own API key, requests still go through Cursor's AWS backend. The Security Page states:
"Note that the requests always hit our infrastructure on AWS even if you have configured your own API key"
The Privacy Policy also spells out more specific conditions:
"We do not use Inputs or Suggestions to train our models, or permit third parties to use them for training, unless: (1) they are flagged for security review (2) you explicitly report them to us (for example, as Feedback), or (3) you've explicitly agreed"
Composer 2 uses Kimi K2.5 (1.04T params / 32B active) as its base model, but inference runs on Fireworks AI's infrastructure, so your code is not sent directly to Moonshot AI's servers.
Devin
How to opt out
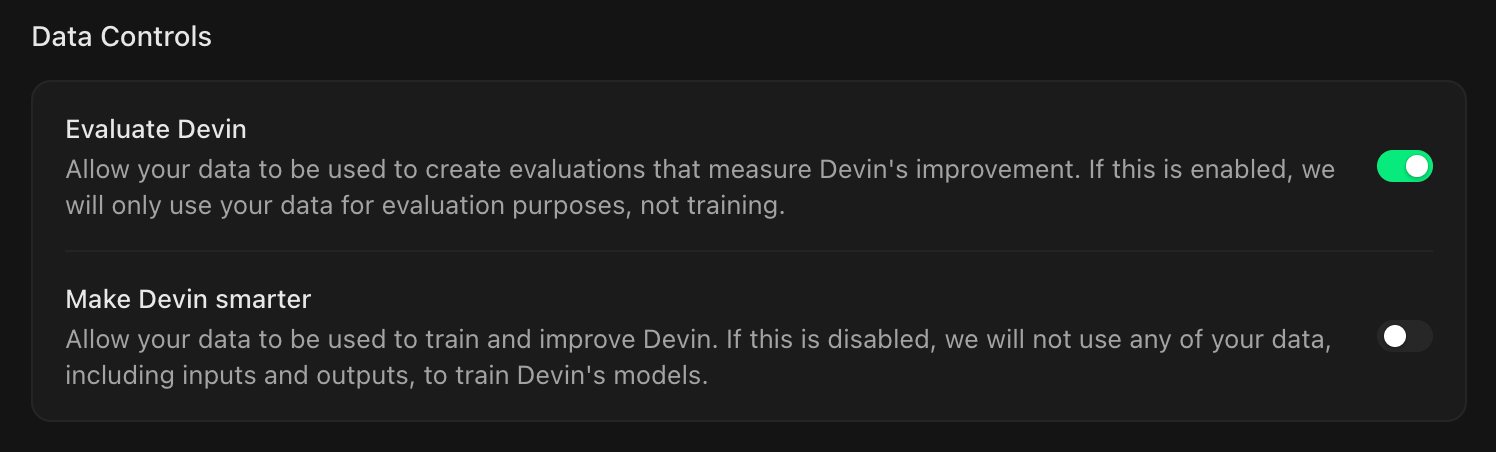
Turn Make Devin smarter OFF at https://app.devin.ai/org/{team-name}/settings/general
- If you also want to opt out of evaluation usage, turn
Evaluate DevinOFF - I think it's interesting that training and evaluation are shown as separate toggles
Terms
The Terms of Service states:
"Any Customer Data that you submit, upload, or otherwise post to the Services will not be used for model training purposes unless you opt-in."
However, the Privacy Policy says something different.
"depending on the terms that apply to your use of the Services, using User Content to train, fine tune and improve the models that power our Services"
The "depending on the terms" language leaves it to the TOS, but depending on how you read it, there's some ambiguity left.
Kiro
How to opt out

Settings > Data Sharing And Prompt Logging > Turn "Content Collection For Service Improvement" OFF
- Turn this OFF to opt out of training usage
Usage Analytics And Performance Metricsis a separate setting for usage telemetry
Terms
The FAQ states:
"We may use certain content from Kiro Free Tier and Kiro individual subscribers...for service improvement"
"We do not use content from Kiro Pro, Pro+, or Power users that access Kiro through AWS IAM Identity Center or external identity provider"
However, there's been a report of a gap between this FAQ promise and AWS Service Terms Section 50.3. The legal terms reserve the right to use data.
WindSurf
How to opt out

- Turn
Disable TelemetryON at https://windsurf.com/settings
Terms
The Terms of Service states:
"We may use your Autocomplete User Content to improve our discriminative machine learning models"
"We may use your Chat User Content to improve the generative and discriminative machine learning models we use."
WindSurf (formerly Codeium) was acquired by Cognition AI in July 2025, and two privacy policies coexist: windsurf.com and cognition.ai. The cognition.ai side also describes training usage.
"customize your experience with our Services and otherwise improve our Services including...using User Content to train, fine tune and improve the models that power our Services"
Note that Team/Enterprise plans have zero data retention enabled by default, but per the Security Page, there's no ZDR agreement with Bing.
"We do not have a zero data retention agreement with Bing."
Kimi Code
How to opt out
Email [email protected]
Terms
The Privacy Policy states:
"User Content: This includes prompts, audio, images, videos, files, and any content you input or generate while using our products and services. We process this information to provide and improve the Services, including training and optimizing our models."
Section 3 of the Terms of Service describes the opt-out:
"You may opt out of allowing your Content to be used for model improvement and research purposes by contacting us at [email protected]."
Summary
- GitHub Copilot flipping to training-ON by default for Free/Pro/Pro+ on April 24 is a significant change. On the flip side, Business/Enterprise gets stronger protection now that no-training usage is explicitly codified
- There are multiple cases where terms aren't fully consistent internally (Devin's TOS vs Privacy Policy, Kiro's docs vs AWS Service Terms, WindSurf's dual policies), so it's worth reading the legal terms in addition to the docs
- If your data does get used for training, you're contributing to model advancement
Appendix: Official terms links for each tool
| Tool | Terms of Service | Privacy Policy |
|---|---|---|
| GitHub Copilot | Generative AI Services Terms / Product Specific Terms (Archive) | Trust Center FAQ |
| Codex | Service Terms | Privacy Policy |
| Claude Code | Legal and Compliance | Privacy Center |
| Antigravity | Antigravity Terms | Google Privacy |
| Cursor | Data Use Overview | Privacy Policy |
| Devin | Terms of Service | Privacy Policy |
| Kiro | Data Protection | Privacy and Security |
| WindSurf | TOS (Individual) | Privacy Policy |
| Kimi Code (Moonshot AI / Kimi) | Terms of Service | Privacy Policy |
References
- GitHub Generative AI Services Terms
- GitHub Copilot Product Specific Terms (March 2026, Archive)
- GitHub Docs: Manage policies for Copilot
- OpenAI: Your Data
- Codex Security
- Updates to Consumer Terms and Privacy Policy - Anthropic
- Claude Code Data Usage
- Claude flips the privacy default - Smith Stephen
- Antigravity Terms
- Antigravity Data Training Opt-Out Discussion
- Cursor Data Use Overview
- Cursor Security Page
- Cursor Privacy Policy
- Composer 2 Technical Report
- Cognition AI Terms of Service
- Cognition AI Privacy Policy
- Kiro FAQ
- Kiro Data Protection
- WindSurf Terms of Service (Individual)
- WindSurf Security Page
- JP Caparas, "Kimi K2.5 is brilliant, but think twice about using Kimi.com"
This article is based on publicly available information as of March 21, 2026, and was updated on March 27, 2026 to reflect the latest terms for each tool. Terms may change at any time.