Building HarnessBench, a Benchmark for Coding Agent Harnesses
by 逆瀬川ちゃん
7 min read
Hi there! This is Sakasegawa-chan (@gyakuse)!
Today I want to write about HarnessBench, a benchmark I built for comparing coding agent harnesses.
What I Built
When people talk about Coding Agent performance, they often talk only in terms of model names: GPT-5.5 is strong, Opus is strong, Composer is fast, and so on.
But what we actually use in development is not the raw model. We use a harness such as Codex CLI, Claude Code, or Cursor Agent. The harness decides how the agent reads a repository, runs commands, edits files, handles memory, receives prompts, manages permissions, emits logs, and uses caches. The same model can behave differently under a different harness.
So I built HarnessBench.
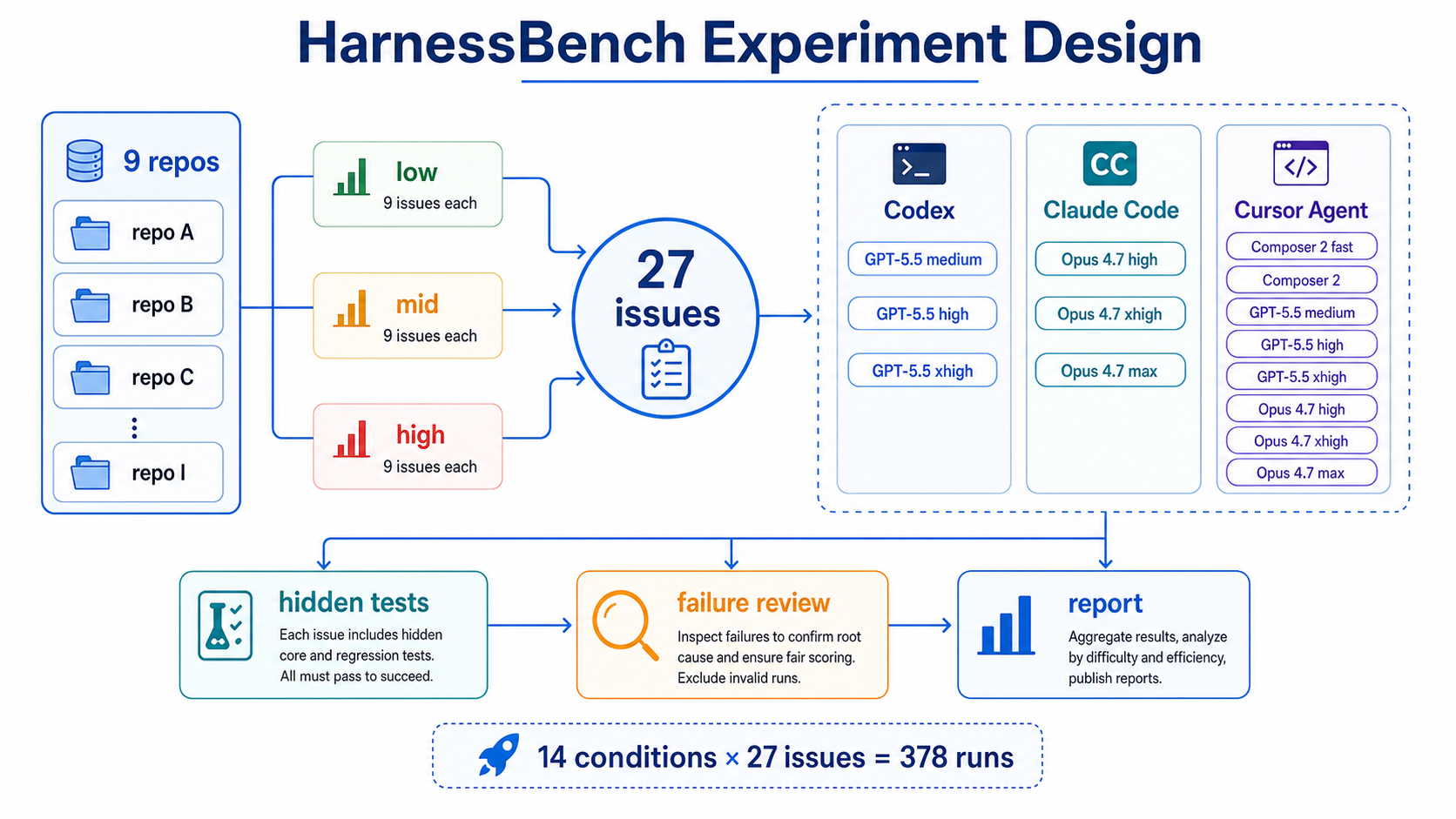
The benchmark unit is:
| Item | Value |
|---|---|
| Repositories | 9 real OSS repositories |
| Tasks | 3 issues per repository: low / mid / high, 27 total |
| Conditions | 14 Codex / Claude Code / Cursor Agent conditions |
| Runs | 27 tasks × 14 conditions = 378 runs |
| Scoring | deterministic hidden tests: core + regression |
The result page and repository are here:
Why Compare Harnesses?
I want to explain why I compared harnesses rather than only comparing models.
Coding Agent capability is not just the model, and not just the harness. It is the combination of the two.
Looking through related work, there are already benchmarks based on real OSS PRs, benchmarks scored with hidden tests, and benchmarks comparing multiple agents. But I could not find a public benchmark that compares Codex CLI / Claude Code CLI / Cursor Agent CLI side by side on the same tasks. PerfBench, SWE-Compass, HWE-Bench, and Multi-SWE-bench are close, but they are not primarily benchmarks of production CLI harnesses.
I also cared about benchmaxxing: the problem where a model or agent looks good because it is over-optimized for public benchmarks, or because solutions leak through training data or repository history. NIST's discussion of cheating in agent evaluations mentions future commits and solution contamination in SWE-bench-style evaluations. HarnessBench is not a private benchmark, but it tries to reduce that risk by using relatively recent Pull Requests, recording base/fixed commits, using hidden tests, and explicitly sanitizing repository-local steering files.
The point is not simply whether model A is better than model B. I wanted to see what changes when GPT-5.5 runs under Codex versus Cursor, or when Opus 4.7 runs under Claude Code versus Cursor.
Scoring with Hidden Tests
The most dangerous part of comparing harnesses is letting the grader itself wobble. HarnessBench therefore does not use LLM-as-a-judge as the primary score.
Each task is scored by hidden tests. The tasks were created by collecting recent Pull Requests, selecting bug-fix PRs at an appropriate granularity, and verifying that the base commit fails while the fixed commit passes. Then I wrote hidden tests for user-visible behavior rather than for the PR diff itself, and I reviewed failed agent runs to fix tests that were too narrow and could cause false negatives.
| Layer | Meaning |
|---|---|
core_tests |
the observable contract required to say the bug is fixed |
regression_tests |
nearby behavior that must remain intact |
At first, I considered an oracle-suite layer that enumerated acceptable implementation paths. I eventually removed it. If multiple fixes are valid, it is clearer to write the core test as a behavioral class than to enumerate implementation routes. The score should care about user-visible behavior, not whether the agent edited the same file as the original PR.
This is close to the functional-correctness lineage of HumanEval and SWE-bench. At the same time, it shares the concern of work like STING, SWE-ABS, and UTBoost: tests themselves can be weak. In this benchmark, false-negative review was part of the process, and overly strict tests were revised.
Experimental Conditions
The official run used 14 conditions. Every run had a 60-minute timeout per issue. I did not run repeated trials.
| Harness | Conditions |
|---|---|
| Codex CLI | GPT-5.5 medium / high / xhigh |
| Claude Code | Claude Opus 4.7 high / xhigh / max |
| Cursor Agent | Composer 2 fast / normal, GPT-5.5 medium / high / extra-high, Claude Opus 4.7 high / extra-high / max |
For baseline conditions, harness memory and repository-local steering were disabled. Otherwise files such as AGENTS.md, CLAUDE.md, .codex, .claude, and .agents can unintentionally steer the solution. HarnessBench sanitizes those files before running the agent.
Results
First, pass rate. The top observed condition was Codex / GPT-5.5 / xhigh at 22/27.
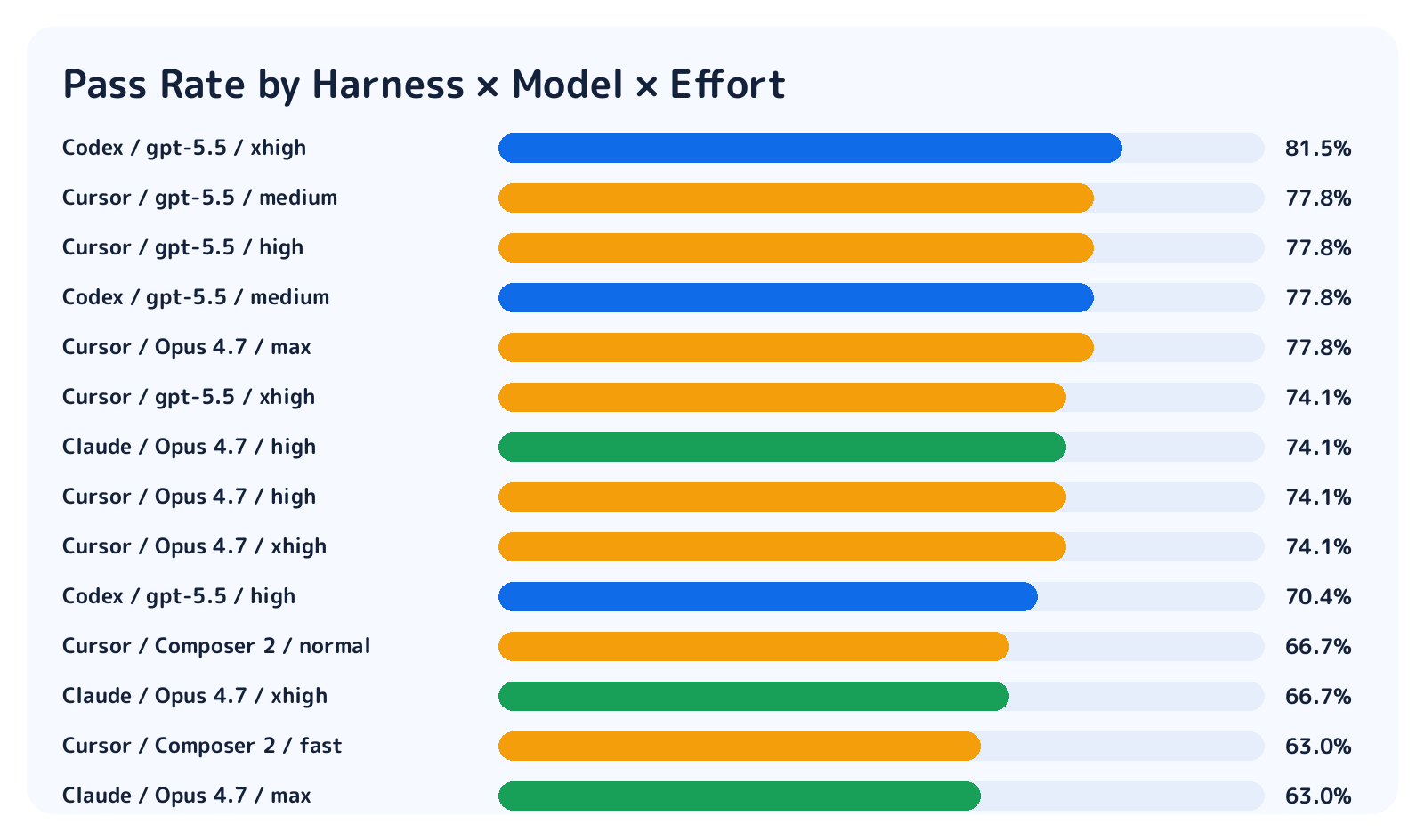
| Condition | Pass |
|---|---|
| Codex / GPT-5.5 / xhigh | 22/27 |
| Codex / GPT-5.5 / medium | 21/27 |
| Cursor / Opus 4.7 / max | 21/27 |
| Cursor / GPT-5.5 / high | 21/27 |
| Cursor / GPT-5.5 / medium | 21/27 |
The important caveat is that with only 27 tasks, the success-rate differences were not statistically significant. There is an observed ranking, but I would not claim that one condition is definitively stronger. To reliably detect a 10-point gap, we probably need roughly 160-315 tasks.
Runtime differences were much clearer.
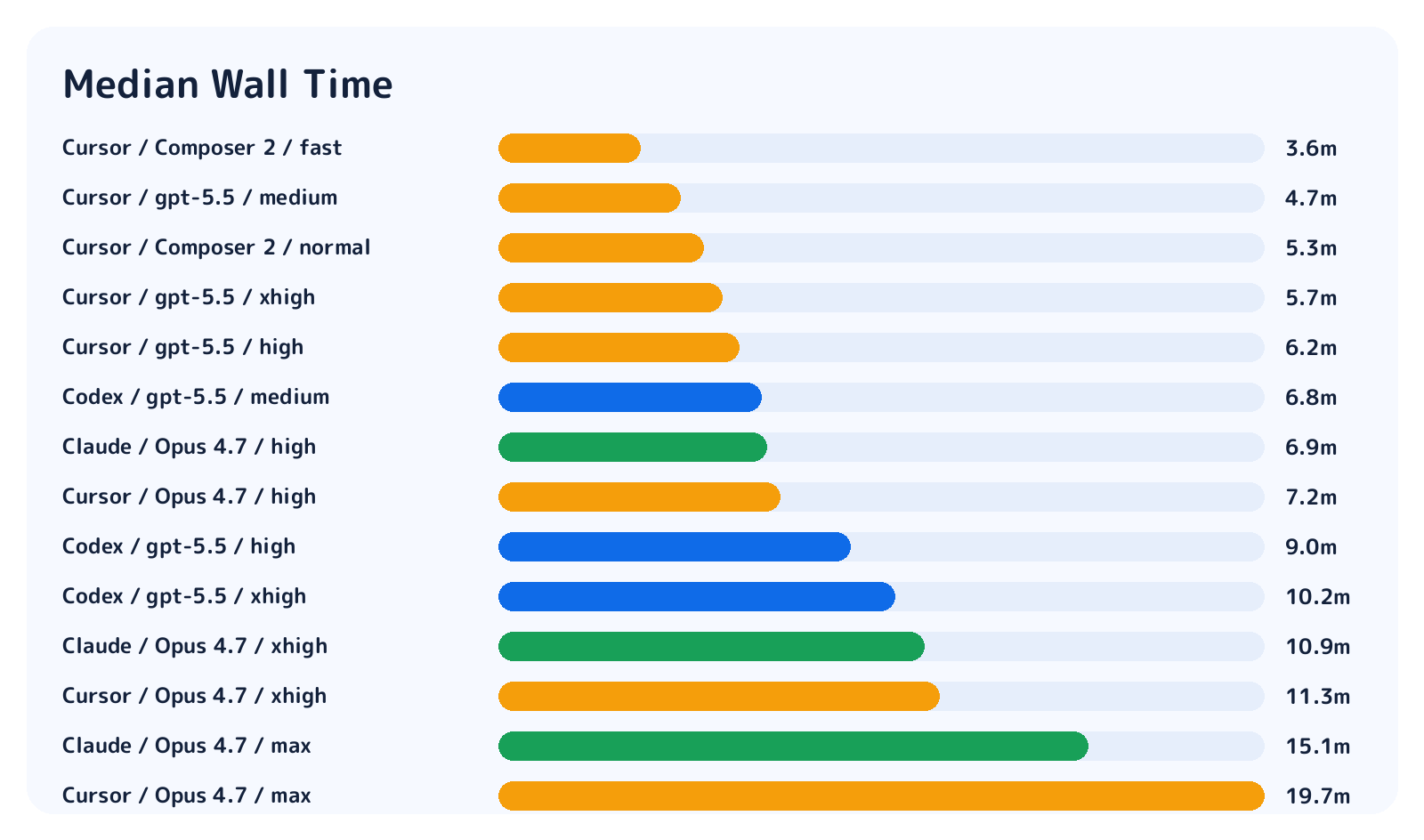
Cursor Composer 2 fast had a median wall time of 3.6 minutes, and Cursor GPT-5.5 medium was 4.7 minutes. Codex GPT-5.5 xhigh was 10.2 minutes, Claude Opus max was 15.1 minutes, and Cursor Opus max was 19.7 minutes.
There were 6 timeouts in total: 1 for Claude Code Opus high, 2 for Claude Code Opus xhigh, 2 for Claude Code Opus max, and 1 for Cursor Opus high. Even with a 60-minute limit, some high-effort Claude Code runs did not reach a natural stop.
So the picture changes when we look at runtime together with pass rate.
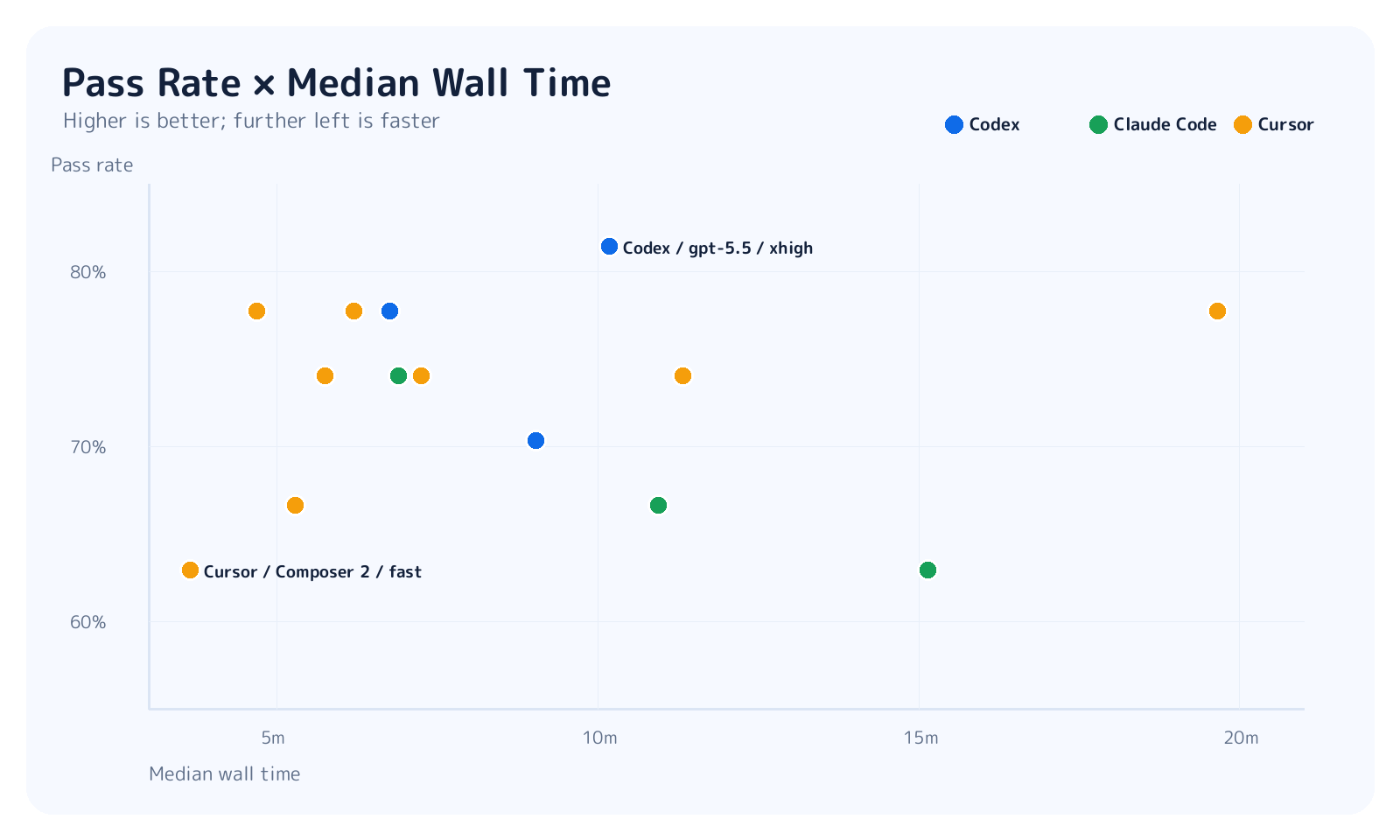
Cursor GPT-5.5 medium/high looks like a strong speed/accuracy tradeoff. Codex GPT-5.5 xhigh had the highest observed pass rate, but it took more time and cost than medium. Opus max variants spent more time reasoning, but in this 27-task run that did not translate into a statistically reliable success-rate gain.
Results by Difficulty
Here is the same result broken down by difficulty. Overall pass rate alone hides where the differences come from.
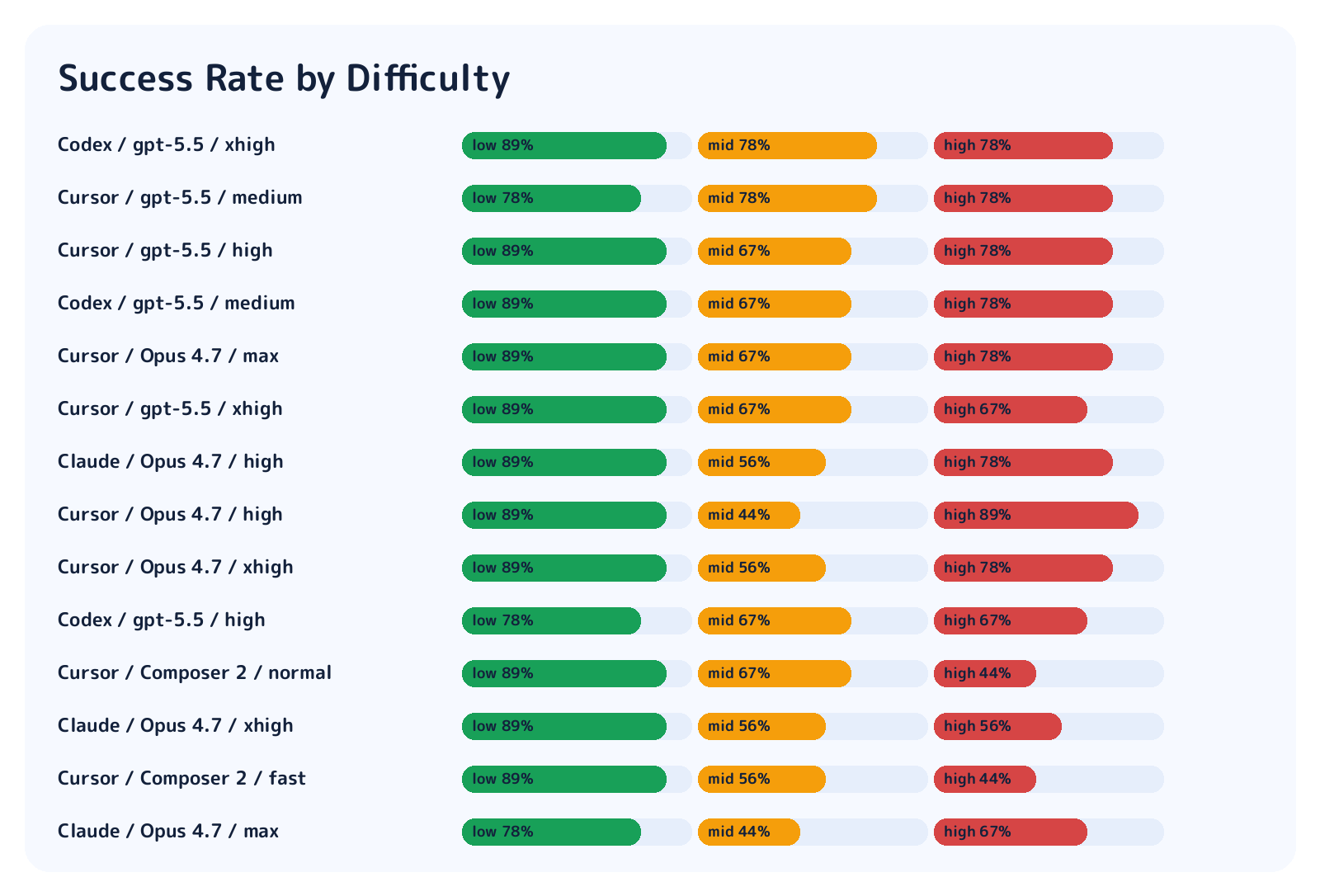
As expected, high-difficulty tasks were harder. But low-difficulty tasks were not all solved either. Even low tasks failed from misreading the prompt, breaking nearby behavior, or missing timeout handling.
That is a good property for a benchmark. If low is too easy, harness differences disappear. If high is impossible, there is nothing to analyze. The official run had 275/378 passes overall, which is a useful range: neither too coarse nor too brittle.
What the False-Negative Review Showed
Failed runs were reviewed with LLM-as-a-judge as an auxiliary tool. This was not the scoring mechanism. The score came from hidden tests. The review was used to ask: is this a true failure, is the test too strict, or is the case design unclear?
The review categories were:
| Category | Meaning | Action |
|---|---|---|
| true failure | the implementation does not satisfy the required behavior | keep the failure |
| false-negative candidate | the implementation looks plausible but the hidden test is too narrow | fix the hidden test and regrade |
| case design issue | the instruction is too ambiguous, or the task is a poor benchmark case | revise the instruction or case |
This is the messiest part of building a benchmark. Sometimes you think you are observing agent failures, but you are actually observing grader weakness. SWE-bench-style work also treats hidden-test insufficiency and contamination as major issues.
HarnessBench keeps the LLM out of the primary score and uses it only as an auditor for failures. This is not perfect, but it is more stable than letting the LLM decide which answer it likes.
What I Learned
The conclusions are intentionally modest.
First, harness differences are real. Even in similar model tiers, behavior changes with logging, exploration style, command execution, caching, and timeout handling.
Second, 27 tasks are not enough to make strong success-rate ranking claims. The observed differences are interesting, but statistically weak. That does not mean we learned nothing. It tells us how much larger the benchmark needs to become.
Third, runtime is a strong signal. If two conditions solve roughly the same number of tasks, the faster one is often more useful in practice. Wall time deserves to be a first-class metric.
Fourth, Composer 2 did much better than I expected. Honestly, I was somewhat suspicious that Composer 2 might be a benchmaxxing-heavy model: strong on other benchmarks, but less useful for real debugging work. In this run, however, Cursor Composer 2 fast solved 17/27 and normal Composer 2 solved 18/27. Given the speed, that is a very practical level of accuracy. It was not the top condition, but it was clearly not just a benchmark mirage.
Next Steps
The benchmark skeleton is now in place. The next step is simple: add more tasks.
To make stronger claims about success-rate differences, 27 tasks are not enough. I want at least 100 tasks, ideally 200-300. But adding tasks without maintaining hidden-test quality would make the benchmark worse, not better.
The next improvements are:
- add more tasks
- structure failure review more rigorously
- tighten harness version drift and Docker environment records
- compare additional harnesses and prompt-intervention conditions
Summary
- HarnessBench compares Codex / Claude Code / Cursor Agent on the same 27 tasks
- success-rate differences were not significant at 27 tasks, but runtime differences were visible
- Composer 2 was more useful than I expected on real debugging tasks