Coding Agent比較用の独自のベンチマーク、Harness Benchを作ってみた話
by 逆瀬川ちゃん
8 min read
こんにちは!逆瀬川ちゃん (@gyakuse) です!
今日はHarness向けのベンチマークとして作ったHarnessBenchについてまとめていきたいと思います。
作ったもの
まずは今回作ったものの全体像から見ていきます。Coding Agentの性能を話すとき、モデル名だけで話してしまうことが多いです。GPT-5.5が強い、Opusが強い、Composerが速い、みたいな話です。
しかし実際に開発で使うものはモデルそのものではなく、Codex CLI、Claude Code、Cursor Agentのようなharnessです。harnessはリポジトリの読み方、コマンド実行、ファイル編集、メモリ、プロンプト、権限、ログ形式、キャッシュの扱いを全部持っています。同じモデルでもharnessが変わると結果が変わります。
そこでHarnessBenchというものを作ってみました!
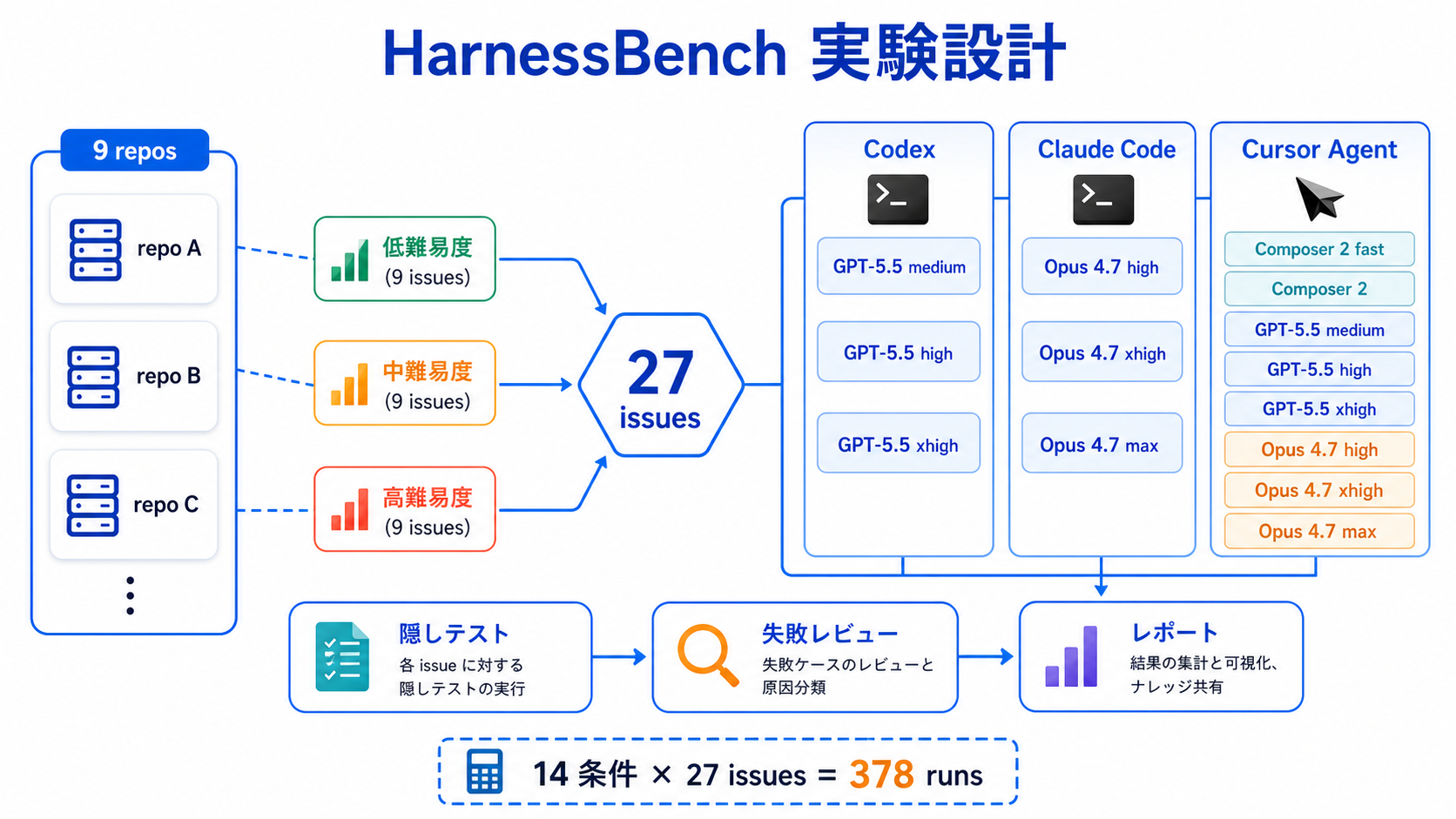
ベンチマークの単位は以下です。
| 項目 | 内容 |
|---|---|
| リポジトリ | 9個の実OSSリポジトリ |
| 課題 | 各リポジトリ low / mid / high の3問、合計27問 |
| 条件 | Codex / Claude Code / Cursor Agent の14条件 |
| 実行数 | 27問 × 14条件 = 378 runs |
| 採点 | hidden test による core + regression の機械採点 |
今回の結果ページはここに置いています。
harnessの比較をしたい
今回なぜモデル比較ではなく、harnessの比較をしたのか、というモチベーションについて少し書きます。
Coding Agentの能力差はモデル単体でなく、harnessでもなく、その組み合わせにあります。
先行研究を調べても、実OSS PR起点のベンチマーク、hidden test採点、複数agent比較はそれぞれ存在します。しかしCodex CLI / Claude Code CLI / Cursor Agent CLIを同じ問題で横並び比較する公開ベンチマークは見当たりませんでした。PerfBench、SWE-Compass、HWE-Bench、Multi-SWE-benchなどが近いですが、商用CLI harnessを主対象にした比較ではありません。
もう一つ気にしたのがbenchmaxxingです。公開ベンチマークに対してモデルやエージェントが過剰に最適化される、あるいは学習データやリポジトリ履歴から解法を見てしまう問題です。NISTのagent evaluation cheating解説でも、SWE-bench系の評価でfuture commitやsolution contaminationが問題になる例が挙げられています。HarnessBenchでは完全な非公開ベンチではないものの、できるだけ新しいPull Requestを起点にcaseを作り、base/fixed commit、hidden test、sanitizationを明示して、既存ベンチへの過適合だけを測ってしまうリスクを下げています。
ここで見たいのはモデルAがモデルBより強いかだけではありません。同じGPT-5.5をCodexで使う場合とCursorで使う場合、同じOpus 4.7をClaude Codeで使う場合とCursorで使う場合、何が変わるのかです。
hidden testで採点をする
さて、harnessを比較するときに一番まずいのは、採点器そのものが揺れることです。そこでHarnessBenchではLLM-as-a-judgeを主採点に使っていません。
採点は各問題に付属するhidden testで行います。問題自体はまず最近のPull Requestを収集し、バグ修正として適切な粒度のPull Requestを選び、base commitでは失敗しfixed commitでは通ることを確認して作っています。そのうえで、PRの差分そのものではなくユーザーから見える挙動をhidden testとして書き、agentの失敗runを見ながらfalse negativeになっているテストは修正しました。
| レイヤー | 意味 |
|---|---|
| core_tests | バグが直ったと言うための観測可能な契約 |
| regression_tests | 周辺挙動を壊していないことの確認 |
最初は正解実装の経路を列挙するoracle suiteも検討したのですが、最終的には削ることにしました。正解が複数あるなら、実装経路を列挙するよりも、core testを満たすべき挙動のクラスとして書いたほうが透明です。PRと同じファイルを編集したかではなく、ユーザーから見える挙動が直っているかを見ます。
この考え方はHumanEvalやSWE-benchの機能的正解性の系譜に近いです。一方で、STING、SWE-ABS、UTBoostのようなテスト自体の強さを疑う研究の問題意識もあります。実際に今回もfalse negative調査を入れて、テスト側が厳しすぎるケースは直しました。
実験条件
公式runでは14条件を走らせました。すべて1 issueあたり60分timeoutです。反復実験はしていません。
| Harness | 条件 |
|---|---|
| Codex CLI | GPT-5.5 medium / high / xhigh |
| Claude Code | Claude Opus 4.7 high / xhigh / max |
| Cursor Agent | Composer 2 fast / normal、GPT-5.5 medium / high / extra-high、Claude Opus 4.7 high / extra-high / max |
ベースライン条件では、各harnessのmemoryやプロジェクトローカルのsteeringを無効化しています。これをやらないと、リポジトリ内のAGENTS.mdやCLAUDE.md、.codex、.claude、.agentsのようなファイルが意図せず問題解決を誘導します。HarnessBenchはそれらをsanitizationしてからエージェントを走らせます。
結果
まず成功率です。トップはCodex / GPT-5.5 / xhighの22/27でした。

| 条件 | Pass |
|---|---|
| Codex / GPT-5.5 / xhigh | 22/27 |
| Codex / GPT-5.5 / medium | 21/27 |
| Cursor / Opus 4.7 / max | 21/27 |
| Cursor / GPT-5.5 / high | 21/27 |
| Cursor / GPT-5.5 / medium | 21/27 |
ただし、ここはかなり大事ですが、27問では成功率の統計的有意差は出ていません。見た目には順位がありますが、この条件が明確に強いとまでは言えません。10ポイント程度の差を安定して検出するには、ざっくり160〜315問くらい欲しくなります。
一方で実行時間はかなり差が見えました。
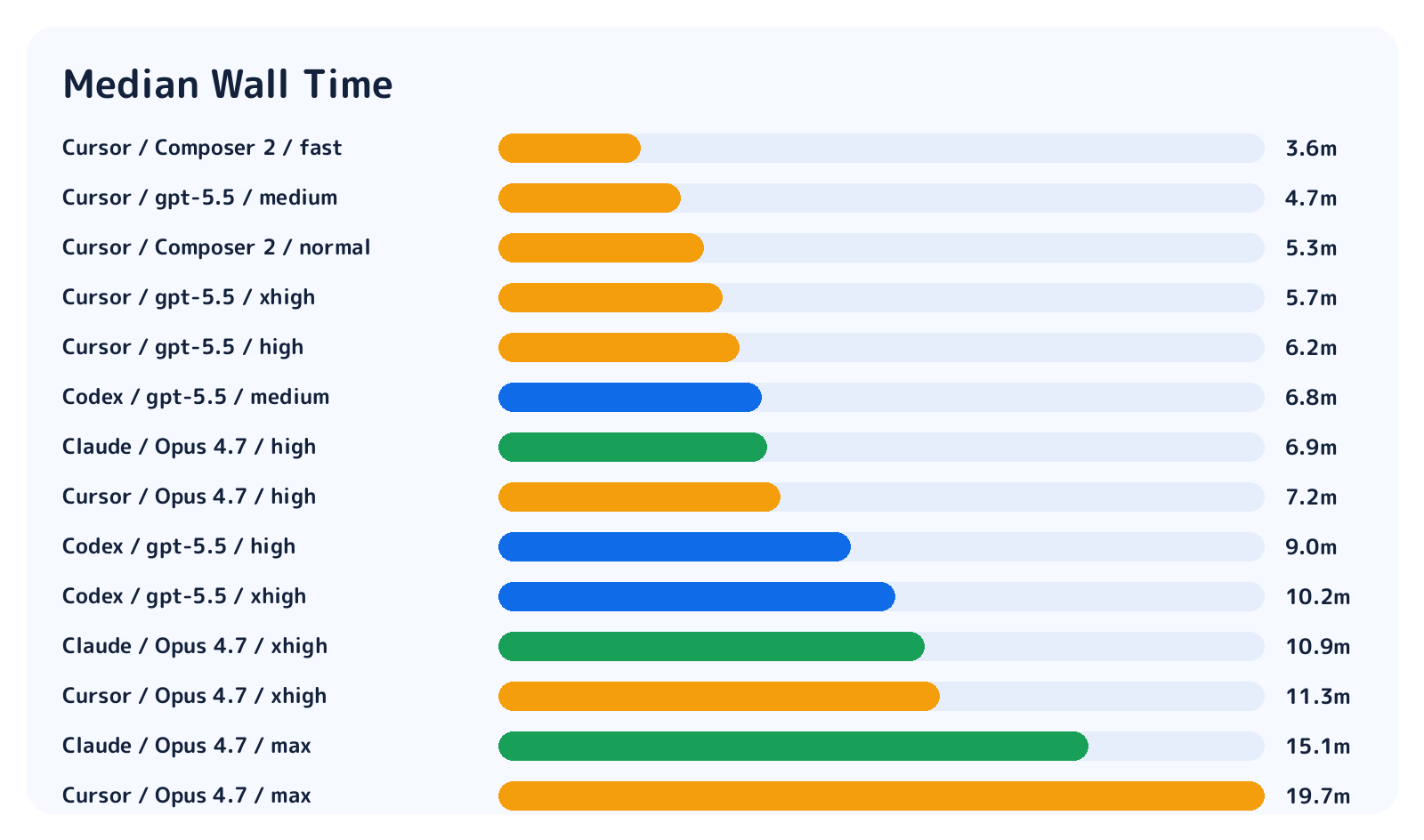
Cursor Composer 2 fastは中央値3.6分、Cursor GPT-5.5 mediumは4.7分でかなり速いです。Codex GPT-5.5 xhighは10.2分、Claude Opus maxは15.1分、Cursor Opus maxは19.7分でした。
timeoutは全体で6件ありました。内訳はClaude Code Opus highが1件、xhighが2件、maxが2件、Cursor Opus highが1件です。60分制限にしても、Claude Codeの高effort帯では一部の問題で最後まで自然停止しないrunが残りました。
さて、成功率だけ見ると小さい差ですが、実行時間を合わせて見ると読み方が変わります。
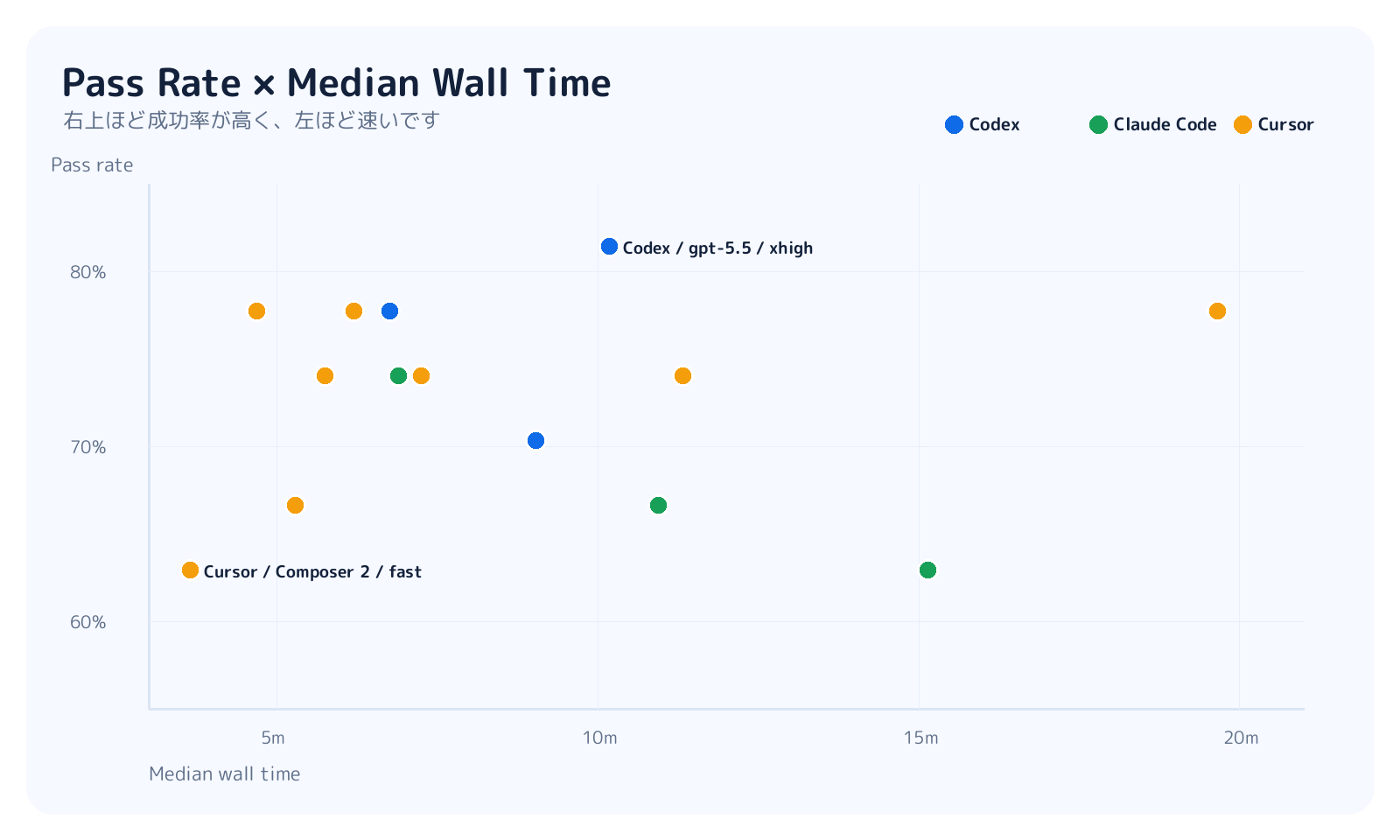
Cursor GPT-5.5 medium/highあたりは速度と成功率のバランスが良く見えます。Codex GPT-5.5 xhighは今回の最高成功率ですが、mediumより時間もコストも上がります。Opus max系は長く考えるものの、今回の27問では成功率の明確な上積みとしては観測できませんでした。
難易度別の結果
次に、同じ結果をdifficulty別に見ていきます。全体のpass rateだけでは、どの難度で差が出ているのかが見えにくいからです。
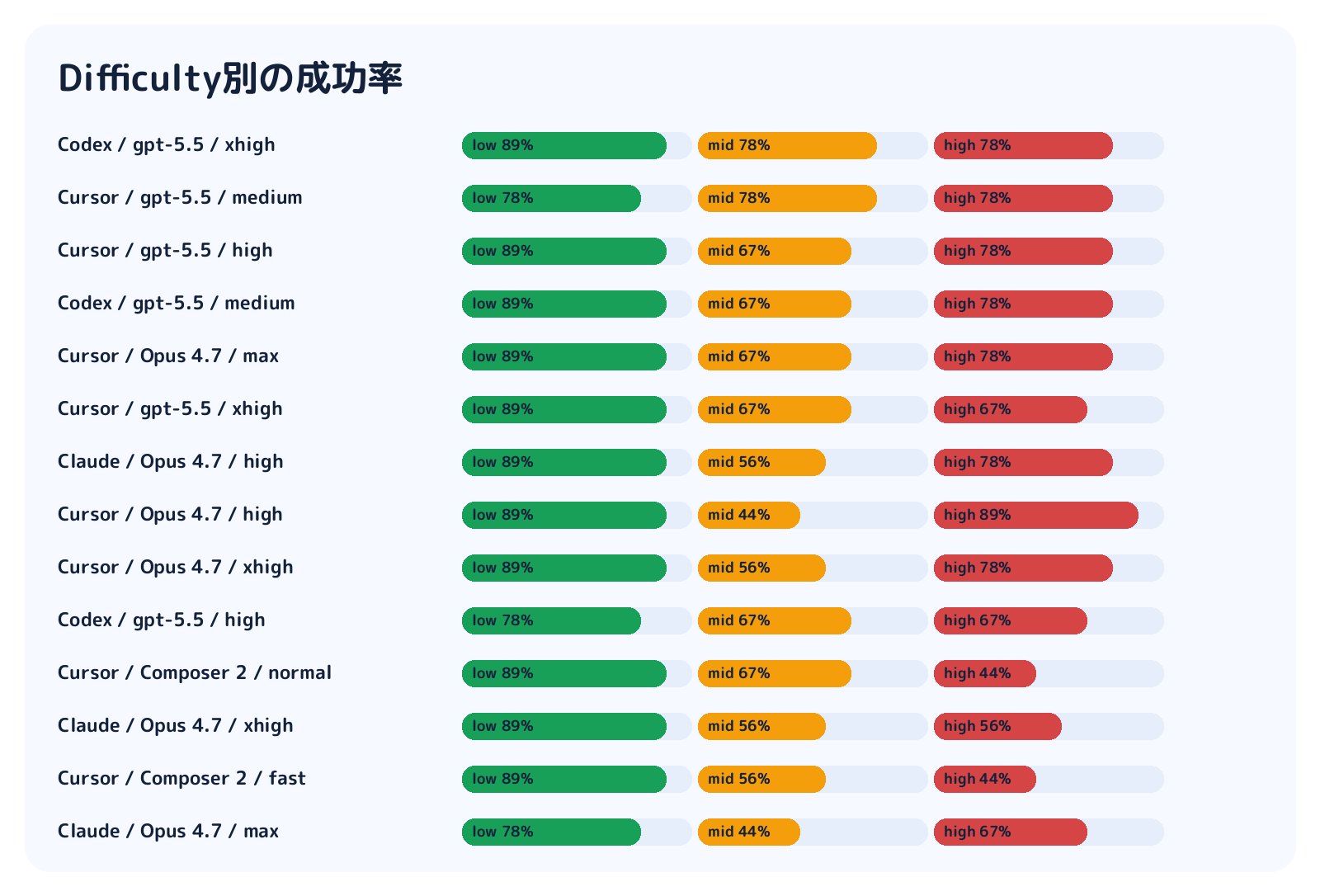
当然ですが、highのほうが落ちます。ただ、lowで全部が解けるわけでもありません。低難度でも、問題文の読み違い、周辺挙動の破壊、タイムアウト処理の抜けなどで失敗します。
このあたりはベンチマークとしては良い性質です。lowが簡単すぎるとharness差が出ませんし、highが全滅すると分析できません。今回は全体で275/378 passなので、粗すぎず細かすぎずのレンジには入っています。
false negative調査で見えたこと
今回、失敗runはLLM-as-a-judgeで補助レビューしています。ただしこれは採点ではありません。採点はhidden testで固定し、レビューは本当に失敗なのか、テストが厳しすぎないか、問題文が誘導不足ではないかを見るための補助です。
レビューで見つかったものは大きく3つです。
| 分類 | 意味 | 対応 |
|---|---|---|
| true failure | 実装が要求挙動を満たしていない | スコアはfailのまま |
| false negative候補 | 実装は妥当に見えるがhidden testが狭い | hidden testを修正してregrade |
| case design issue | 指示が曖昧すぎる、または問題として悪い | instructionやcaseを修正 |
ここはベンチマーク作りで一番泥臭いところです。エージェントの失敗を見ているつもりで、実は採点器の不備を見ていることがあります。SWE-bench系の研究でも、hidden test不足やcontaminationはかなり大きい問題として扱われています。
HarnessBenchでは、採点をLLMに任せず、LLMは失敗の監査役に留めています。これは完全ではありませんが、少なくともLLMが好きな回答を正解にするよりは壊れにくいです。
何がわかったか
今回の結果から言えることは、かなり控えめです。
1つ目は、harness差は実際に観測できるということです。同じようなモデル帯でも、ログ形式、探索の粘り方、コマンド実行、キャッシュ、timeoutの扱いで振る舞いが変わります。
2つ目は、成功率ランキングだけで語るには27問では足りないということです。成功率の差は見えますが、統計的にはまだ弱いです。これは何もわからないという意味ではなく、次に増やすべき規模が見えたという意味です。
3つ目は、速度差はかなり強いシグナルだということです。実用上は同じくらい解けるなら速いほうが良い場面が多いので、wall timeはかなり重要な評価軸になります。
4つ目は、Composer 2が思ったよりかなり健闘したことです。正直、私はComposer 2について、ほかのベンチマークでは強く見えるが実際のデバッグでは使いにくい、いわゆるbenchmaxxing寄りのモデルではないかと少し疑っていました。しかし今回の実リポジトリ課題では、Composer 2 fastが17/27、通常のComposer 2が18/27を通しており、速度を考えると十分に実用的な精度を出しています。もちろんトップではありませんが、単なる見かけ倒しではない、というのは今回の大きな発見でした。
今後
さて、今回でベンチマークの骨格はできました。次にやるべきことは単純で、問題数を増やすことです。
成功率差をもっと確かに言うには、27問では足りません。少なくとも100問以上、できれば200〜300問規模が欲しいです。一方で、1問あたりのhidden test品質を落とすと意味がないので、ただ増やすだけではダメです。
今後は以下を強化していきたいです。
- 問題数を増やす
- failure reviewをより構造化する
- harness version driftやDocker実行環境の記録をさらに固める
- 追加のharnessやprompt intervention条件を比較する
まとめ
- HarnessBenchはCodex / Claude Code / Cursor Agentを同じ27問で比較するベンチマークです
- 27問では成功率の有意差はまだ出ませんでしたが、実行時間の差はかなり見えました