Building a Hiragana ASR: A Clumsy but Cute Speech Recognition Model
by 逆瀬川ちゃん
20 min read
Hi there! This is Sakasegawa-chan (@gyakuse)!
Today I want to share the story of a speech recognition model I built from scratch that outputs only hiragana. Why hiragana instead of mixed kanji-and-kana text, why Whisper didn't work for me, and how combining it with an LLM produces a practical voice dialogue system: I'll walk through the background, the implementation, and the evaluation results in one go.
Watch on YouTube / GitHub / HuggingFace Model / Spaces Demo
What I built
A real-time hiragana ASR that runs on a MacBook Air M2. Microphone input is chopped up by a VAD and each utterance is transcribed into hiragana. The real-time factor (RTF) lands around 0.02 to 0.05, comfortably real-time.
Key features:
- Outputs only hiragana (no kanji at all)
- Hallucinations cannot occur by construction
- Lightweight at 315M parameters (less than half of Whisper large-v3)
- Easy to fine-tune (CTC + wav2vec2 fine-tuning)
- Simultaneously outputs phonemes (InterCTC)
- Delegates kanji conversion and semantic understanding to an LLM downstream
Background
Problems with regular ASR
Japanese speech recognition has three big challenges.
The first is hallucinations. Attention-based encoder-decoder models like Whisper sometimes produce content that isn't in the audio. They may output news-like sentences over silence or loop the same phrase forever. Szymanski et al. (2025) systematically studied the hallucinations non-speech audio triggers in Whisper and found that specific hallucination strings show up repeatedly (the "Bag of Hallucinations"). Wang et al. (2025) went further and pinned down that only 3 out of 20 self-attention heads in the Whisper-large-v3 decoder are responsible for over 75% of all hallucinations.
The second is weight. Whisper large-v3 has 1.55B parameters, which is too heavy for edge devices. Even distilled variants like Kotoba-Whisper still have the autoregressive decoder, which is fundamentally slow.
The third is how hard it is to fine-tune state-of-the-art models. ReazonSpeech k2-v2, one of the most accurate Japanese ASR models, uses the Zipformer architecture (Yao et al., ICLR 2024) on top of the Next-gen Kaldi (k2) framework. k2 ships in ONNX so inference is fast, but fine-tuning requires understanding the entire k2 / Lhotse / icefall toolchain, which makes casual fine-tuning on your own data pretty much out of reach.
Why hallucinations happen
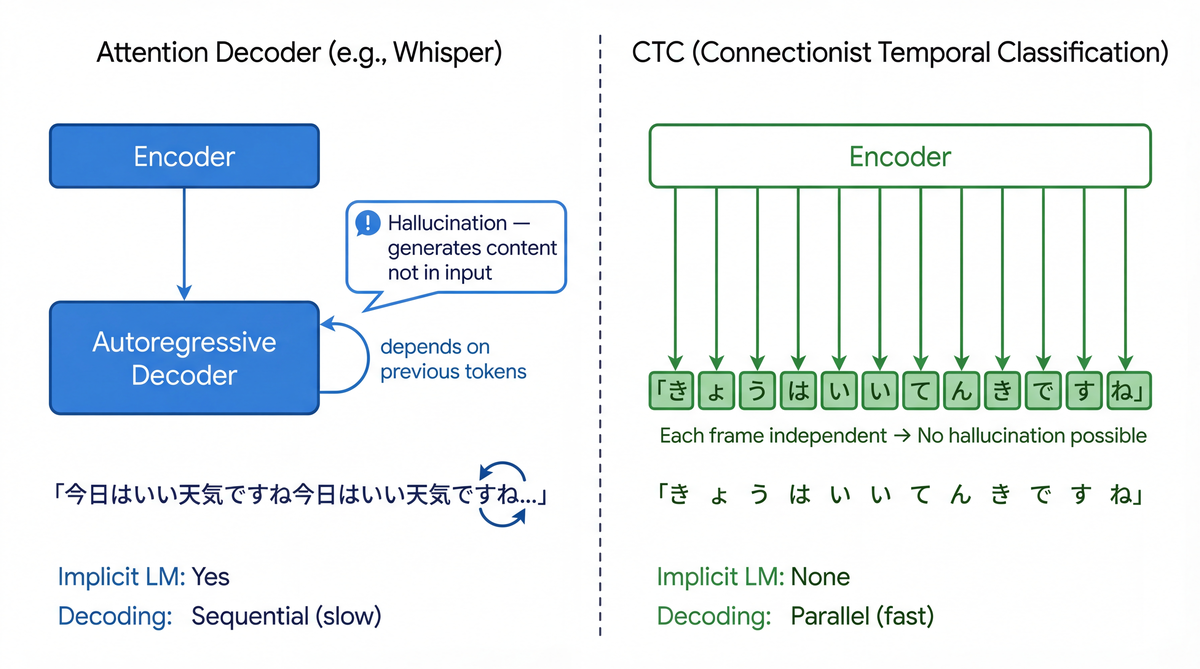
The root cause of hallucinations is the autoregressive decoder architecture.
Attention-based encoder-decoders like Whisper have this shape:
Audio → Encoder → cross-attention → Decoder (autoregressive)
↑ conditions on previously generated tokens
Because the decoder generates each token conditioned on previous tokens, it implicitly acts as a language model. That is one of Whisper's strengths, but it also creates a fatal weakness.
- When the encoder output is ambiguous (noise, silence, etc.), the decoder falls back on its "language-model knowledge" and manufactures sentences
- Mitigations like loop detection and repetition penalties are well-studied, but at the core this is a problem caused by the autoregressive structure itself, and fully eliminating it is hard
- Atwany et al. (ACL 2025) proposed a new metric called the Hallucination Error Rate (HER) and showed its correlation with distribution shift is a remarkable α=0.91
Meanwhile CTC (Connectionist Temporal Classification, Graves et al., ICML 2006) operates under the constraint of "emit outputs along the input's time order," and each frame's output does not depend on other frames' outputs (the conditional independence assumption). That means it has no language modeling ability, but it also means it is structurally incapable of producing content that isn't in the input.
| Property | Attention Decoder | CTC |
|---|---|---|
| Language modeling | Implicit | None |
| Hallucination | Can occur | Structurally impossible |
| Decoding speed | Slow (sequential) | Fast (parallel) |
| Alignment | Flexible (can reorder) | Fixed to input order |
| Output diversity | High | Low |
Motivation
I want to chat with an AI assistant
I wanted a system where I could talk to an AI assistant by voice. Not a text chat but a natural voice interface.
When you look at it this way, "accuracy" in ASR starts to mean something slightly different. Typical ASR evaluation asks "can we transcribe this into correct mixed kanji-kana text?" But for voice dialogue, what matters is "can the LLM correctly understand the intent?" Taken to the extreme, even hiragana works fine as long as the sounds are written correctly, because the LLM can still figure out the meaning.
Modern approaches to voice dialogue
Voice dialogue systems in 2024–2026 split into roughly three approaches.
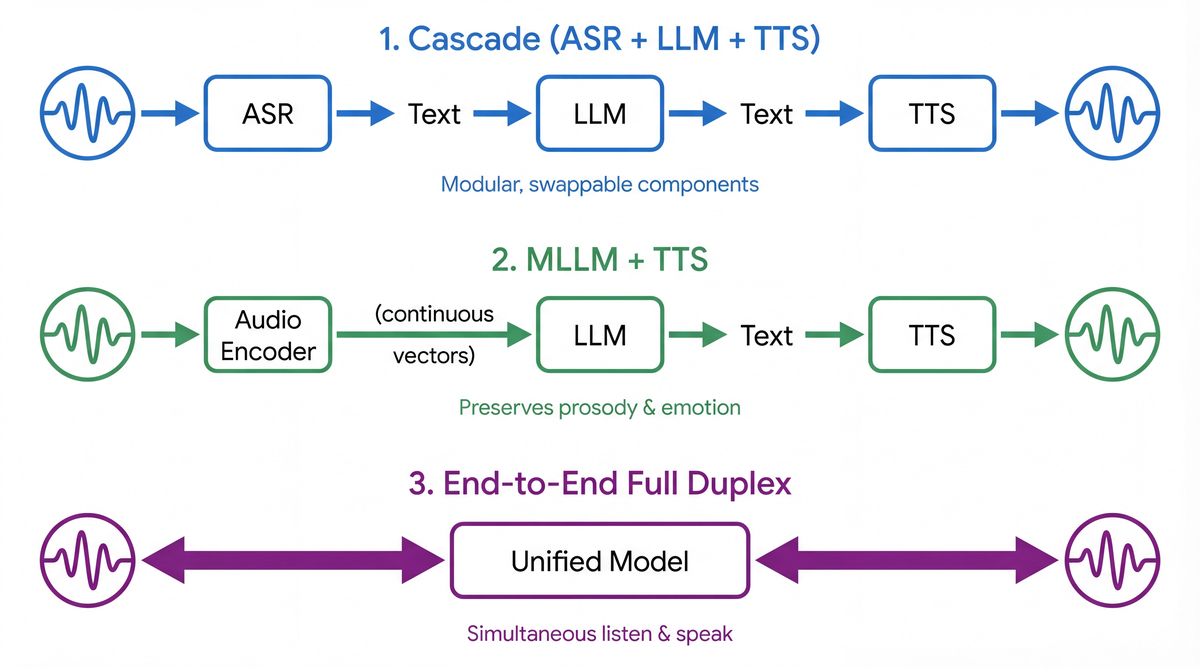
1. ASR + LLM + TTS (cascade)
The simplest and most battle-tested approach. Its strength is modularity: you can independently improve or swap out any component. X-Talk (2024) argues the cascade is underrated and demonstrates that a systematically optimized cascade pipeline beats open-source end-to-end systems on latency, interruption handling, and complex audio understanding.
2. MLLM + TTS (multimodal LLM)
Audio is converted to continuous vectors by an encoder and injected directly into the LLM. SALMONN (Tang et al., ICLR 2024) combines a Whisper encoder and a BEATs encoder to feed an LLM. Qwen2-Audio (2024) and WavLLM (Microsoft, EMNLP 2024) are in the same category. The benefit is that you avoid the information loss that happens when you turn audio into text (prosody, emotion, speaker characteristics).
3. End-to-end full duplex models
Models that handle input and output simultaneously and can start responding while the other party is still talking. The closest to human conversation.
How MLLMs recognize speech
The way MLLMs consume audio splits into two broad camps.
Discrete tokens: audio is turned into discrete tokens by a neural audio codec (EnCodec, Mimi, SpeechTokenizer, etc.) and processed in the same vocabulary space as text tokens. GLM-4-Voice (2024) uses an extremely low-bitrate single codebook at 175 bps.
Continuous vectors: output from a speech encoder (Whisper encoder, wav2vec2, HuBERT, etc.) is mapped into the LLM's embedding space through an adapter layer (Q-Former, linear projection, etc.). The comparative study in Wang et al. (EMNLP 2025) shows continuous features beat discrete tokens on many tasks, while discrete tokens win on phoneme recognition.
What full duplex is
Full duplex is a dialogue mode where you can speak and hear the other person at the same time. Natural human conversation is exactly this: you can drop in "uh-huh" or "oh" and cut in while someone is still talking.
Cascade full duplex: adds turn-taking control on top of the ASR + LLM + TTS pipeline. FireRedChat (2025) supports both cascade and semi-cascade modes, suppressing false barge-ins with a streaming VAD.
End-to-end full duplex: Moshi (Kyutai, 2024) was the first practical end-to-end full duplex model. It models two audio streams (user and system) in parallel and dramatically improves generation quality via "Inner Monologue" (predicting text tokens aligned with its own audio). It achieves a theoretical latency of 160ms and a practical 200ms.
J-Moshi (Ohashi et al., Interspeech 2025) is the first Japanese full duplex model, pre-trained on the J-CHAT corpus (roughly 69,000 hours) and acquires Japanese-specific behaviors like frequent backchannels and speech overlap.
MinMo (2025) uses 8B parameters and 1.4 million hours of speech data, achieving roughly 100ms speech-to-text latency and roughly 600ms full duplex latency. More recently, VITA-Audio (NeurIPS 2025) proposed an MCTP module that generates multiple audio tokens in one forward pass, achieving 3–5x inference speedups.
GPT-4o is a unified omni model that achieves a 232ms response latency (OpenAI, 2024), and Gemini 2.5 is a sparse MoE architecture that supports native voice dialogue in over 80 languages (Google DeepMind, 2025).
| Model | Approach | Latency | Languages | Year |
|---|---|---|---|---|
| GPT-4o | Unified omni | 232ms | Multilingual | 2024 |
| Gemini 2.5 | Sparse MoE | - | 80+ languages | 2025 |
| Moshi | E2E full duplex | 200ms | English | 2024 |
| J-Moshi | E2E full duplex | - | Japanese | 2025 |
| MinMo | E2E full duplex | 600ms | Chinese/English | 2025 |
| VITA-Audio | E2E + MCTP | - | Multilingual | 2025 |
Reducing ASR errors with an LLM
These cutting-edge E2E models are tempting, but building a full duplex model from scratch as an individual developer isn't realistic. With a cascade you can build and improve each component independently.
What matters here is the strategy of using an LLM to compensate for ASR errors.
HyPoradise (Chen et al., NeurIPS 2023) established the Generative Error Correction (GER) paradigm of passing ASR N-best hypotheses to an LLM for error correction. The LLM can generate tokens that aren't even in the N-best list, which gives it capabilities beyond traditional language model rescoring.
For Japanese, Ko et al. (2024) built a GER benchmark and proposed Multi-Pass Augmented GER, which merges hypotheses from multiple ASR systems via an LLM. Homophone recall on medical text improved from 27.6% to 85.0%.
Yamashita et al. (Interspeech 2025) go a step further and improve rare-word correction accuracy by adding phoneme information (simplified kana notation) to what the LLM sees.
Here one particular framing starts to stand out.
MLLM voice dialogue injects continuous vectors into the LLM via a speech encoder. ASR+LLM injects transcribed text into the LLM. I figured a hiragana ASR + LLM sits somewhere in between.
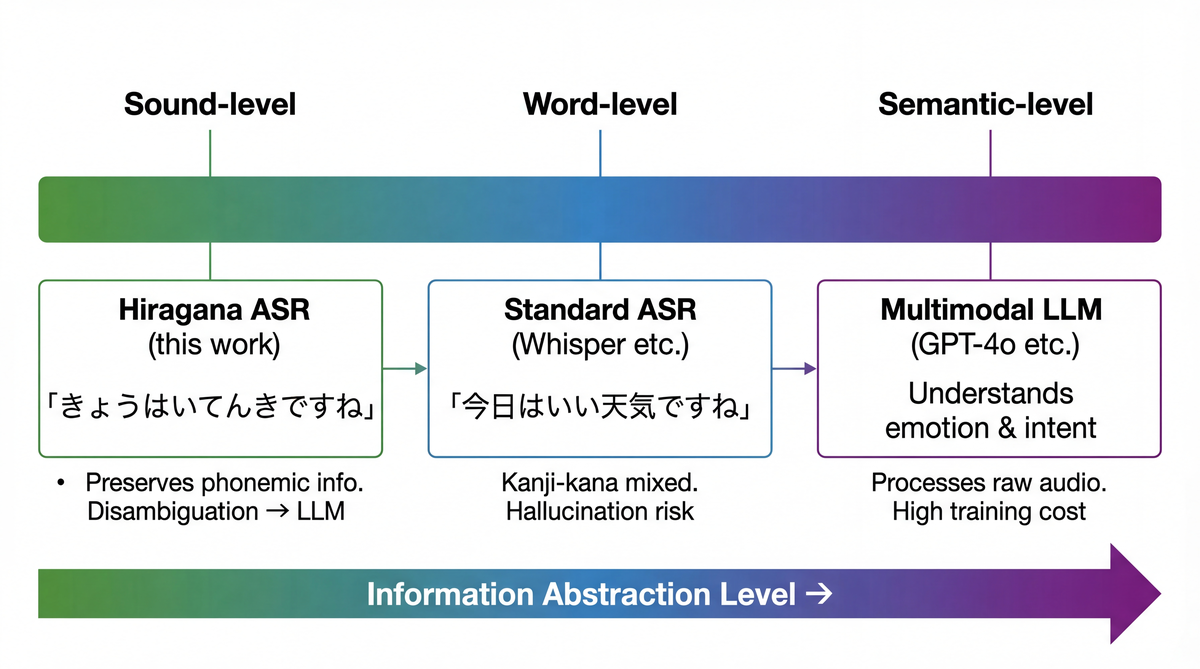
Hiragana writes sounds directly, so there's no information distortion from kanji conversion. Pass "はしをわたる" to an LLM as-is and it can interpret it as "橋を渡る" (cross a bridge). Resolving homophones is exactly what LLMs are good at. Ma et al. (Interspeech 2025) show that LLM-based phoneme-to-grapheme conversion outperforms WFST-based systems, backing up the idea that LLMs are well suited to phonetic representation → text conversion.
Training strategy
Given all of this background, I designed the ASR model with the following policies.
- Hiragana-only output: delegate homophone disambiguation to the LLM. Kanji output causes vocabulary explosion and training data volume problems
- CTC-based: eliminate hallucinations by construction. No autoregressive decoder
- Leverage wav2vec2 pre-training: use a Japanese-specific pre-trained model (reazon-research/japanese-wav2vec2-large), pre-trained on 35,000 hours of ReazonSpeech v2.0 (2024)
- Dual CTC (InterCTC): simultaneously output phonemes alongside hiragana. Predict phonemes at an intermediate layer and hiragana at the final layer. An architecture that combines Lee & Watanabe's (ICASSP 2021) InterCTC with Han et al.'s (Apple, Interspeech 2024) Diverse Modeling Units
- CR-CTC: adopt Consistency Regularization CTC from Yao et al. (ICLR 2025) to mitigate CTC's well-known spike issue (Zeyer et al., 2021)
- Runs on M2 Air: 315M parameters, 630MB on disk in FP16. Inference via the MPS backend
Dataset preparation
For training data I used ReazonSpeech (NLP 2023), a large-scale Japanese speech corpus built from terrestrial TV broadcasts. It includes a diverse set of audio conditions: emotional speech, BGM, fast speakers, proper nouns, and so on.
| Split | Hours | Samples | Use |
|---|---|---|---|
| tiny | 8.5h | ~5,000 | Debugging |
| small | 100h | ~62,000 | Early experiments |
| medium | 1,000h | ~619,000 | Production training |
Two kinds of training labels are auto-generated.
Hiragana labels: pyopenjtalk's g2p(text, kana=True) converts the text to katakana, which is then normalized to hiragana. Alphabets are expanded into katakana pronunciations ("A" → "エー"). Punctuation is removed. Tokenization is one character at a time, space-separated. Vocabulary size is 84 (82 hiragana + long-vowel mark + CTC blank).
Phoneme labels: pyopenjtalk's g2p(text, kana=False) converts to a phoneme sequence. pau / sil are removed so only meaningful phonemes remain. Vocabulary size is 43 (42 phonemes + CTC blank). The OpenJTalk phoneme set is consistent with the standard Japanese ASR 37–43 phoneme set (Tamaoka & Makioka, 2004).
For preprocessing, FLAC decoding and G2P conversion are done offline, and the waveform/label pairs are saved in HuggingFace Datasets' numpy format. This speeds up data loading during training by over 50x.
I prepared three evaluation datasets.
- JSUT-BASIC5000: single-speaker studio recordings (read speech, 5,000 utterances)
- JVS parallel100: parallel read speech by 100 speakers (roughly 10,000 utterances)
- ReazonSpeech: in-the-wild audio from TV broadcasts (roughly 2,600 utterances)
Model architecture
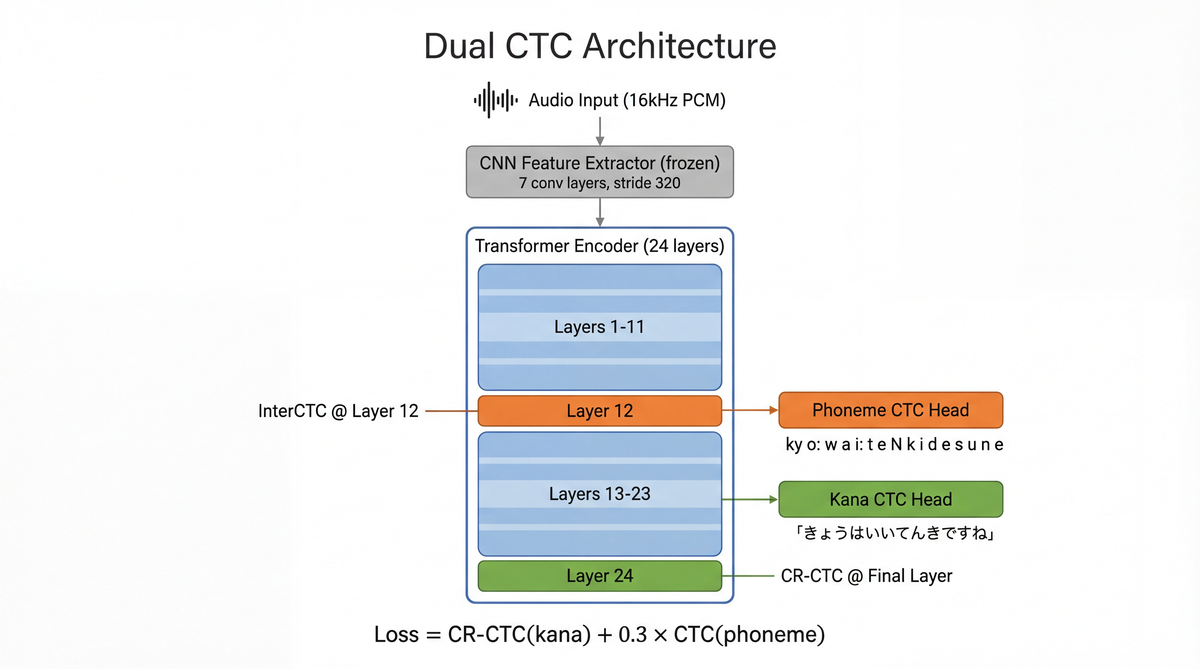
A Dual CTC model based on the pre-trained wav2vec2 encoder (Baevski et al., NeurIPS 2020) with two CTC heads on top.
The intent behind InterCTC: Lee & Watanabe (2021) showed that attaching an auxiliary CTC loss to an intermediate layer improves gradient flow into the lower layers and stabilizes training. Nozaki & Komatsu (Interspeech 2021) introduced Self-Conditioned CTC, which conditions later layers on intermediate predictions to relax CTC's conditional independence assumption. I don't do any conditioning here; I adopt the Diverse Modeling Units approach from Han et al. (2024), using different granularity targets (phonemes in the middle, hiragana at the end).
Introducing CR-CTC: CTC loss tends to produce spiky distributions (Zeyer et al., 2021). Adding a regularization term on the KL divergence between adjacent frames pushes the output distribution to be smoother. I set the regularization weight to 0.1.
The loss function is:
L = CR-CTC(hiragana) + 0.3 × CTC(phoneme)
Breaking down the CR-CTC term, it is CTC(hiragana) + 0.1 × KL regularization.
Parameter count is 315.6M (of which the CNN feature extractor is frozen). At inference time FP16 takes about 630MB, which leaves plenty of room on a 16GB M2 Air (LoRA-INT8 Whisper, 2025 reports an INT8 model achieving RTF=0.20 on a MacBook M1 Max).
Training
Training was done in two stages.
Stage 1: initial experiments on 100h (small)
| Parameter | Value |
|---|---|
| Data | ReazonSpeech small (100h, 62,047 samples) |
| GPU | A100 80GB (RunPod) |
| Batch size | 32 (16 × grad_accum 2) |
| Learning rate | 1e-4 |
| Epochs | 15 |
| Precision | BF16 |
| SpecAugment | mask_time_prob=0.05 |
| Wall clock | About 5 hours |
| Cost | About $6 |
val_loss converged to 1.3588 by epoch 7 and didn't improve after that. At 100h, data volume is the bottleneck.
Stage 2: production training on 1,000h (medium)
| Parameter | Value |
|---|---|
| Data | ReazonSpeech medium (1,000h, 619,104 samples) |
| GPU | H100 80GB (Vast.ai) |
| Batch size | 32 (8 × grad_accum 4) |
| Learning rate | 5e-5 |
| Warmup | 3,000 steps |
| Gradient clipping | 1.0 |
| Epochs | 5 (early stop) |
| Precision | BF16 |
| Bucket batching | Enabled |
| Wall clock | About 8 hours |
| Cost | About $17 |
val_loss converged to 1.5185 around steps 70,000 to 75,000. It hit a plateau partway through epoch 5, so I cut it there.
Step val_loss Event
───── ──────── ──────
5000 1.8505 best
10000 1.6252 best
20000 1.6084 best
35000 1.5387 best
55000 1.5226 best
70000 1.5185 best
75000 1.5185 tied
~79000 (killed) plateau
A few training notes.
Bucket batching: audio lengths vary wildly, so I batch together utterances of similar length. Same idea as the BucketingSampler in Lhotse (Zelasko et al., 2021): minimize padding and push GPU utilization up.
BF16: as Edge-ASR (2025) and Kurtic et al. (ACL 2025) show, BF16 uses the same exponent bits as FP32 (unlike FP16), so it overflows less and doesn't need a GradScaler. wav2vec2's CNN feature extractor tends to NaN out on FP16, but trains stably under BF16.
SpecAugment: using Park et al.'s (Interspeech 2019) method, I mask along the time axis with wav2vec2's built-in mask_time_prob. I kept it conservative at 0.05.
No augmentation: speed perturbation (Huh et al., 2024) and noise injection are implemented but cause CPU bottlenecks, so I disabled them for this run.
Monitoring training with Claude Code
During training I had Claude Code watch over the job. It turns out you can drive this kind of thing interactively, plus hand off bringing up Vast.ai servers and environment setup, which makes it a surprisingly capable companion for future training runs.
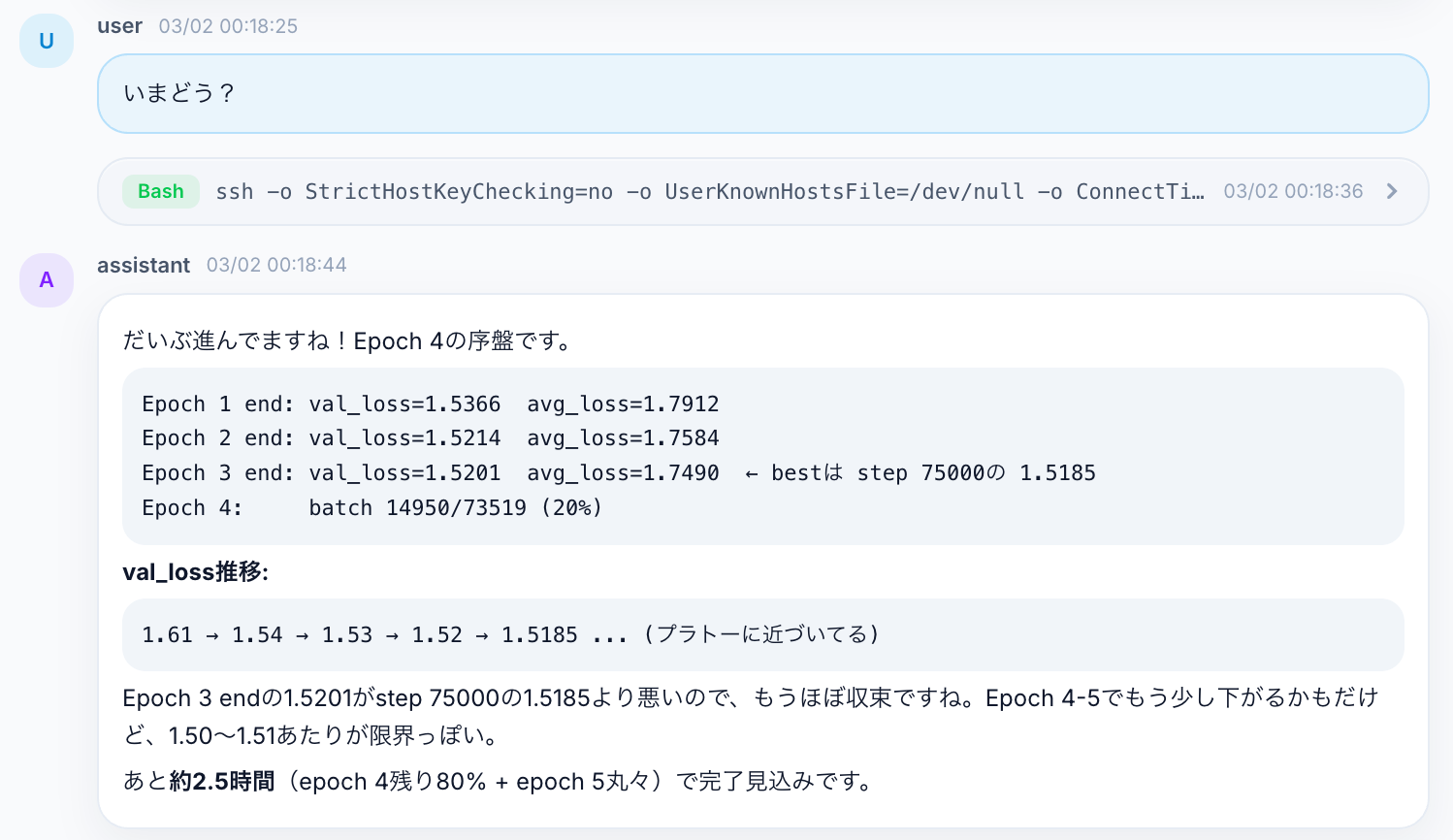
You just ask "how's it going?" and it SSHes into the server, checks the state, and reports on val_loss progression and plateau judgement.
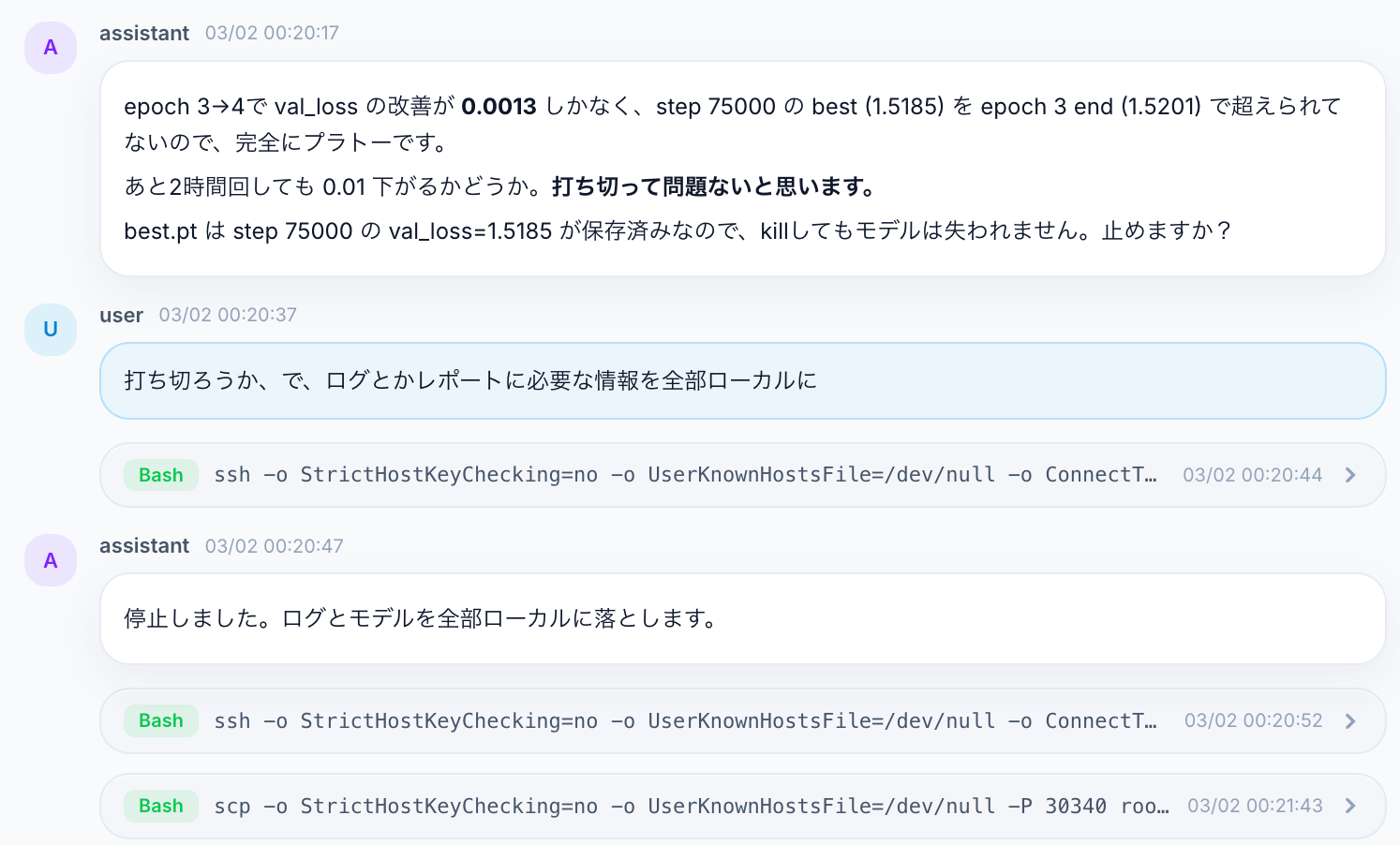
Once it decides the run has plateaued, it proposes stopping it, and can even pull the model and logs down to local. Reassuring even for late-night training.
Evaluation
Results on three datasets.
Overall
| Dataset | Conditions | KER | PER |
|---|---|---|---|
| JSUT | Studio, single speaker | 7.47% | 10.42% |
| JVS | 100 speakers | 15.68% | 21.43% |
| ReazonSpeech | In-the-wild | 21.65% | 21.87% |
KER (Kana Error Rate) is the character-level edit distance on hiragana. Thennal et al. (NAACL 2025) argues that for Japanese ASR, CER (Character Error Rate) is more appropriate than WER (Word Error Rate), but for hiragana-only output I evaluate with KER. That said, as Karita et al. (ACL 2023) points out, Japanese has no fixed orthography (the same word can be written in kanji, hiragana, or katakana), so ordinary CER penalizes spelling variants too harshly. Hiragana-only output sidesteps this problem.
Effect of model size and data volume
| Model | Data | JSUT KER | JVS KER | ReazonSpeech KER |
|---|---|---|---|---|
| wav2vec2-base + 100h | small | 17.9% | - | - |
| wav2vec2-large + 100h | small | 7.5% | - | - |
| wav2vec2-large + 1,000h (ep1) | medium | 7.86% | 17.57% | 24.93% |
| wav2vec2-large + 1,000h (ep5) | medium | 7.47% | 15.68% | 21.65% |
Switching from base to large improved JSUT KER by 58% (17.9% → 7.5%). The impact of model size is overwhelming.
Meanwhile, the impact of 10x'ing the data depends on the dataset. In clean conditions (JSUT), 7.5% → 7.47% is essentially flat, but in multi-speaker conditions (JVS) we go 17.57% → 15.68%, and in-the-wild (ReazonSpeech) 24.93% → 21.65%, with the improvements widening. In other words, the extra 1,000h mostly helps generalization to diverse speakers and acoustic conditions.
Error analysis
Looking at the hiragana confusion patterns, clear trends show up.
Weakness 1: katakana words (loanwords)
The hardest class for hiragana ASR is katakana words. Loanwords are already forced into Japanese phonology from foreign languages, and they lean heavily on long-vowel marks and small kana. Words like "にゅーいんぐらんどふー" or "くりーむすーぷ" are hard to read even when written in hiragana, and long-vowel and small-kana errors concentrate on this class.
Weakness 2: the long-vowel mark "ー"
The most unstable token across all datasets. It swaps multiple ways: "ー→ん", "ー→あ", "ー→い", "ー→え". On JVS there are 335 instances of い→ー, 319 of う→ー, and 281 of ー→い.
Weakness 3: small kana
28.1% error rate on JVS. ぉ→ほ (443 times) is the top confusion pair: acoustic discrimination between small "ぉ" and regular "ほ" is tough. In other words, transcribing oh-moaning is not its strong suit.
Weakness 4: vowels
The い↔え confusion is frequent on JSUT (183 times) and ReazonSpeech (33 times). Discriminating adjacent vowels is a bottleneck.
At the phoneme level, the main issues are discriminating devoiced vowels (U↔u, I↔i) and dropped palatalization markers (my→m, by→b, gy→g).
Real-time inference
I built a real-time system that does VAD-based segmentation with Silero VAD and runs ASR per utterance. Silero VAD is a 1.8MB model that can process a 30ms chunk in about 1ms (Snakers4, 2025).
Decoding uses SWD (Spike Window Decoding), which exploits CTC's spike-heavy outputs by only decoding windows around non-blank spikes, keeping accuracy while making inference more efficient.
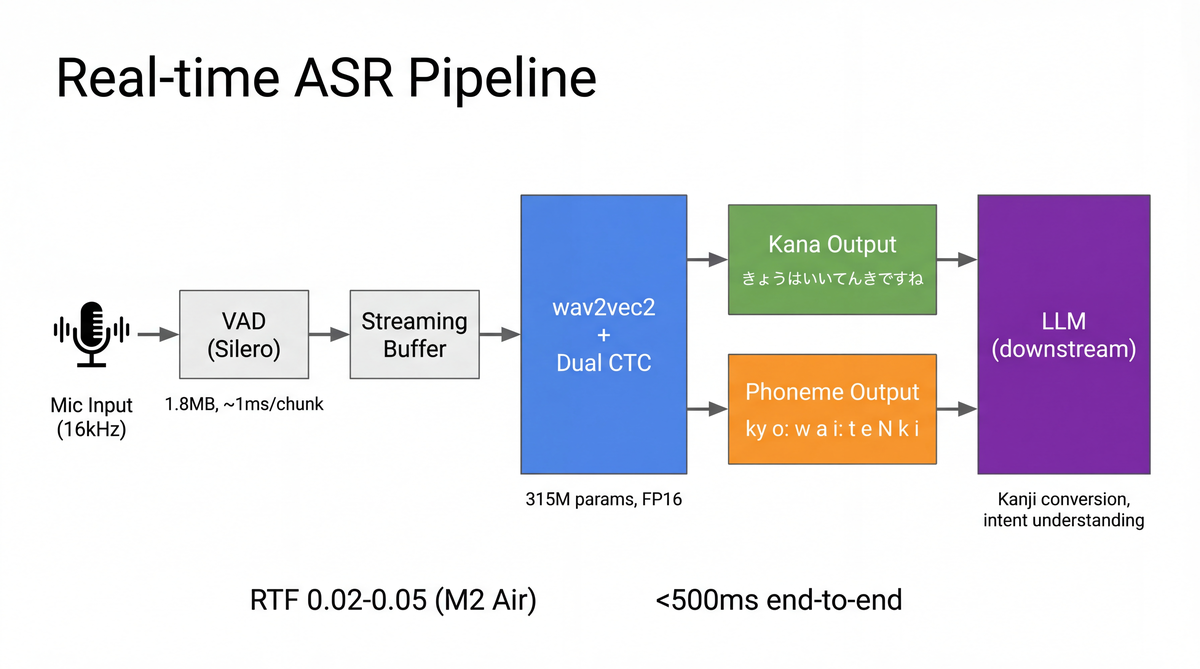
On an M2 Air with FP16 inference, RTF sits in the 0.02–0.05 range. A 15-second utterance is processed in 0.3–0.75 seconds, so there's plenty of headroom for real-time use.
Pairing with an LLM
I also experimented with passing the hiragana output into the Claude API for dialogue. I attach ASR confidence metadata (per-frame softmax probabilities) and include alternate candidates for low-confidence tokens when handing the result to the LLM.
{
"channel": "hybrid",
"hiragana": "きょうはいいてんきですね",
"phonemes": "ky o u w a i i t e N k i d e s u n e",
"confidence_mean": 0.87,
"confidence_min": 0.52,
"low_confidence_tokens": [
{"position": 3, "predicted": "い", "alternatives": ["え", "ー"]}
]
}
The policy is: ask back only when confidence drops below a threshold, otherwise do best-effort intent estimation. Naowarat et al. (Interspeech 2023) proposes confidence estimation methods for CTC models that calibrate better than raw softmax probabilities.
Future directions
Noise robustness
ReazonSpeech KER of 21.65% is still high. Implementing speed perturbation and noise injection on the GPU side and tuning SpecAugment parameters should leave room for improvement. Zhang et al. (2025) improves CER from 26.17% → 16.88% with semantic-aware SpecAugment.
Countermeasures for long-vowel marks and small kana
I'm considering post-processing rule-based corrections and label normalization (such as expanding long vowels into the preceding vowel).
Leveraging pitch accent
As mentioned in the earlier survey, the wav2vec2 encoder retains pitch accent information in its intermediate layers (de la Fuente & Jurafsky, 2024; Koriyama, SSW13 2025). Adding a pitch-accent auxiliary task to the current InterCTC architecture is a natural extension. Kubo et al. (2025) uses a 3-way CTC multitask (katakana + text + F0 classification) and improves Japanese mora-label error rate from 12.3% → 7.1%.
Systematic evaluation of LLM error correction
I'd like to build a benchmark that systematically evaluates intent understanding accuracy for hiragana ASR → LLM. I'll design an evaluation framework specific to hiragana input, building on Ko et al.'s (2024) Japanese GER benchmark.
ONNX / CoreML conversion
sherpa-onnx is ONNX Runtime-based and supports 12 programming languages including mobile, making it an ideal target for an ONNX-converted wav2vec2 + CTC model. Whisper quantization research (2025) reports a 68% model size reduction with INT8 and over 3x CPU-to-CoreML-encoder speedup.
Wrap-up
- A CTC-based hiragana ASR is structurally free of hallucinations, lightweight, and easy to fine-tune
- Delegating homophone resolution to the LLM minimizes the burden on the ASR
- With 1,000 hours of training it hits JSUT KER 7.47% and runs in real time on an M2 Air
Appendix
A. CTC's conditional independence and hallucination resistance
The CTC loss is defined as:
Here π is an alignment path that includes blanks, and B⁻¹ is the inverse image of the CTC collapse function. The key part is ∏ P(π_t | x): each timestep's output probability is conditioned only on the encoder output x and does not depend on other timesteps' outputs.
That means there is architecturally no mechanism to "generate" content not in the input. This is fundamentally different from an attention decoder that conditions on past outputs via P(y_t | y_{<t}, x).
B. Why InterCTC stabilizes training
The lower layers of a deep encoder suffer from gradient attenuation from the final layer. InterCTC applies a CTC loss directly to an intermediate layer, which gives us the following benefits.
- Better gradient flow: computing loss from the intermediate layer directly makes strong gradients flow into the lower layers
- Multitask regularization: different granularity targets (phonemes at the intermediate layer, hiragana at the final layer) encourage the encoder to learn different levels of linguistic abstraction
- Zero inference overhead: the intermediate CTC head can be used only at training time, and you can infer with just the final layer (in this implementation I use both)
C. How CR-CTC works
CR-CTC uses the following loss:
By minimizing the KL divergence between adjacent frames, it regularizes CTC outputs away from being spiky and toward smooth distributions. I set λ=0.1. Yao et al. (2025) propose a more comprehensive formulation that also includes consistency across multiple augmented views; in this implementation I only use consistency between adjacent frames.
References
ASR architectures and methods
- Connectionist Temporal Classification (Graves et al., ICML 2006)
- wav2vec 2.0 (Baevski et al., NeurIPS 2020)
- SpecAugment (Park et al., Interspeech 2019)
- Conformer (Gulati et al., Interspeech 2020)
- Hybrid CTC/Attention (Watanabe et al., IEEE JSTSP 2017)
- Joint CTC/Attention Decoding (Hori et al., ACL 2017)
- Zipformer (Yao et al., ICLR 2024)
CTC improvements
- CR-CTC (Yao et al., ICLR 2025)
- InterCTC (Lee & Watanabe, ICASSP 2021)
- Self-Conditioned CTC (Nozaki & Komatsu, Interspeech 2021)
- Diverse Modeling Units (Han et al., Apple, Interspeech 2024)
- Why does CTC result in peaky behavior? (Zeyer et al., 2021)
- Spike Window Decoding (Zhang et al., ICASSP 2025)
- Alternate Intermediate Conditioning for Japanese ASR (Fujita et al., SLT 2022)
- LAIL: LLM-Aware Intermediate Loss for CTC (2025)
Whisper and hallucinations
- Whisper (Radford et al., ICML 2023)
- Investigation of Whisper ASR Hallucinations (Szymanski et al., ICASSP 2025)
- Calm-Whisper (Wang et al., Interspeech 2025)
- Lost in Transcription (Atwany et al., ACL 2025)
- Listen Like a Teacher (2025)
- Distil-Whisper (Gandhi et al., 2023)
- Kotoba-Whisper v2.0
Japanese ASR
- ReazonSpeech (NLP 2023)
- ReazonSpeech v2.0 (2024)
- Japanese wav2vec2 Models (Reazon, 2024)
- ReazonSpeech k2-v2 (2024)
- Lenient Evaluation of Japanese ASR (Karita et al., ACL 2023)
- Advocating CER for Multilingual ASR (Thennal et al., NAACL 2025)
- Efficient Adaptation for Japanese ASR (Bajo et al., 2024)
- Japanese Phoneme Frequency (Tamaoka & Makioka, 2004)
Voice dialogue and multimodal
- GPT-4o System Card (OpenAI, 2024)
- Gemini 2.5 Technical Report (Google DeepMind, 2025)
- Moshi (Defossez et al., Kyutai, 2024)
- J-Moshi (Ohashi et al., Interspeech 2025)
- MinMo (Alibaba, 2025)
- VITA-Audio (NeurIPS 2025)
- GLM-4-Voice (2024)
- Mini-Omni (Xie et al., 2024)
- X-Talk (2024)
- FireRedChat (2025)
- WavChat Survey (Ji et al., 2024)
- SALMONN (Tang et al., ICLR 2024)
- Qwen2-Audio (2024)
- Qwen3-Omni (2025)
- WavLLM (Microsoft, EMNLP 2024)
- Speech Discrete Tokens vs Continuous Features (Wang et al., EMNLP 2025)
- Recent Advances in Speech Language Models (Cui et al., ACL 2025)
- SpeakStream (Apple, 2025)
LLM × ASR error correction
- HyPoradise (Chen et al., NeurIPS 2023)
- Japanese ASR GER Benchmark (Ko et al., 2024)
- GER for Rare Words with Phonetic Context (Yamashita et al., Interspeech 2025)
- LLM-P2G: Phoneme-to-Grapheme (Ma et al., Interspeech 2025)
- Transducer-Llama (Deng et al., 2025)
- LLM Guided Decoding for SSL ASR (2025)
- Denoising GER (2025)
- GenSEC Challenge (NVIDIA, SLT 2024)
Pitch accent and homophones
- Pitch Accent Detection improves ASR (Sasu & Schluter, Interspeech 2025)
- Building Tailored Speech Recognizers for Japanese (Kubo et al., 2025)
- Prosody Labeling with Speech Foundation Models (Koriyama, SSW13 2025)
- Layer-wise Suprasegmentals in SSL Models (de la Fuente & Jurafsky, 2024)
- Pronunciation Ambiguities in Japanese Kanji (Zhang, ACL 2023)
- CantoASR: Prosody-Aware (Chen et al., 2025)
Confidence estimation
- TruCLeS: CTC/RNN-T Confidence Estimation (Ravi et al., Interspeech 2025)
- C-Whisper: Confidence Estimation (Aggarwal et al., ICASSP 2025)
- Word-level Confidence for CTC (Naowarat et al., Interspeech 2023)
Edge inference and quantization
- LiteASR (EMNLP 2025)
- Moonshine: Tiny ASR for Edge (2025)
- Whisper Quantization Analysis (2025)
- Edge-ASR: Low-Bit Quantization (2025)
- sherpa-onnx (k2-fsa)
VAD and segmentation
Toolkits and data
- ESPnet-SDS (Arora et al., NAACL 2025)
- Lhotse (Zelasko et al., 2021)
- Libriheavy (Kang et al., ICASSP 2024)
Links
- GitHub: nyosegawa/hiragana-asr
- HuggingFace Model: sakasegawa/japanese-wav2vec2-large-hiragana-ctc
- Spaces Demo: sakasegawa/hiragana-asr
- Demo video: YouTube