Are the Agent Skills You Built Actually Working? I Made skill-auditor
by 逆瀬川ちゃん
14 min read
Introduction
Hi there! This is Sakasegawa-chan (@gyakuse)!
Today I want to take on the "unsolved problem" I left dangling at the end of the previous post: the attention competition problem between skills. When you end up with 10 or 20 skills, are they really firing correctly? Did improving one skill's description silently hurt another one? I built a skill that audits this at the portfolio level automatically: skill-auditor (currently Claude Code only).
A quick recap of skill-creator
First, a short look back at Anthropic's skill-creator, which I dug into in the previous post.
skill-creator is "a skill for making skills". When the user says "I want a skill that does X", it runs this cycle:
- Interview to capture intent
- Draft a SKILL.md
- Build test cases and evaluate in parallel (with_skill vs baseline)
- Score, aggregate, and review in an HTML viewer
- Apply feedback and loop on improvements
- Optimize the description (train/test split + Extended Thinking to prevent overfitting)
Structurally, the SKILL.md is a pure orchestrator, and expert prompts like grader.md, comparator.md, and analyzer.md are delegated to sub-agents. A Sub-agent style architecture. Deterministic work goes into scripts, judgment-heavy work goes into sub-agents — Progressive Disclosure applied all the way down into the skill's internals.
The description optimizer is particularly invested: it has three dedicated scripts. It generates 20 test queries, splits them 60/40 into train/test, improves with Extended Thinking (budget_tokens=10000), up to 5 iterations. Picking the best by test score avoids overfitting.
For a detailed walkthrough of skill-creator, see the previous post.
The problem with skill-creator: controlling inter-skill attention competition
skill-creator's Description Optimization is great, but as I noted last time, its handling of attention competition has room to improve.
The competition environment isn't controlled
In skill-creator's optimization loop, it temporarily creates a command file for the skill under test and evaluates it with claude -p. This means the other skills installed in the user's environment are loaded alongside, so to some extent it is testing in a competitive environment.
But that competitive environment isn't controlled. Which skills are sitting next to yours depends on whoever's running it, and the eval set has no relative judgments like "for this query, skill B should fire instead of skill A". If you optimize a skill's description to be "pushier", a neighbor skill can pay the price, and there's no mechanism to detect that.
The concept of an Attention Budget
Agent Skills have a design principle that "the context window is a shared resource". Let me make that concrete.
When the router picks a skill, it reads every skill's description to decide. What matters here is that attention competition depends on the number of directives, not raw token count. A skill at 200 tokens with two clear directives competes less than a skill at 100 tokens crammed with 8 vague ones. In other words, "just make it shorter" isn't the whole story.
How Many Instructions Can LLMs Follow at Once? quantifies exactly this. As the number of instructions grows, LLM compliance drops; even frontier models fall to 68% at 500 instructions. The degradation pattern varies by model: some drop sharply around 150 instructions (threshold decay), some degrade linearly, some collapse early. And the finding that primacy effects ("instructions written earlier take priority") peak at moderate instruction densities hints that the ordering of descriptions can itself affect accuracy.
If you visualize the total tokens spent by all skill descriptions as the "Attention Budget", the health of the whole portfolio becomes visible.
The Whack-a-Mole problem
Here's the tricky bit: whack-a-mole.
When you add a keyword to skill A's description to strengthen it, if that keyword overlaps with skill B's domain, skill B's accuracy drops. Fix skill B and now skill C suffers, and so on.
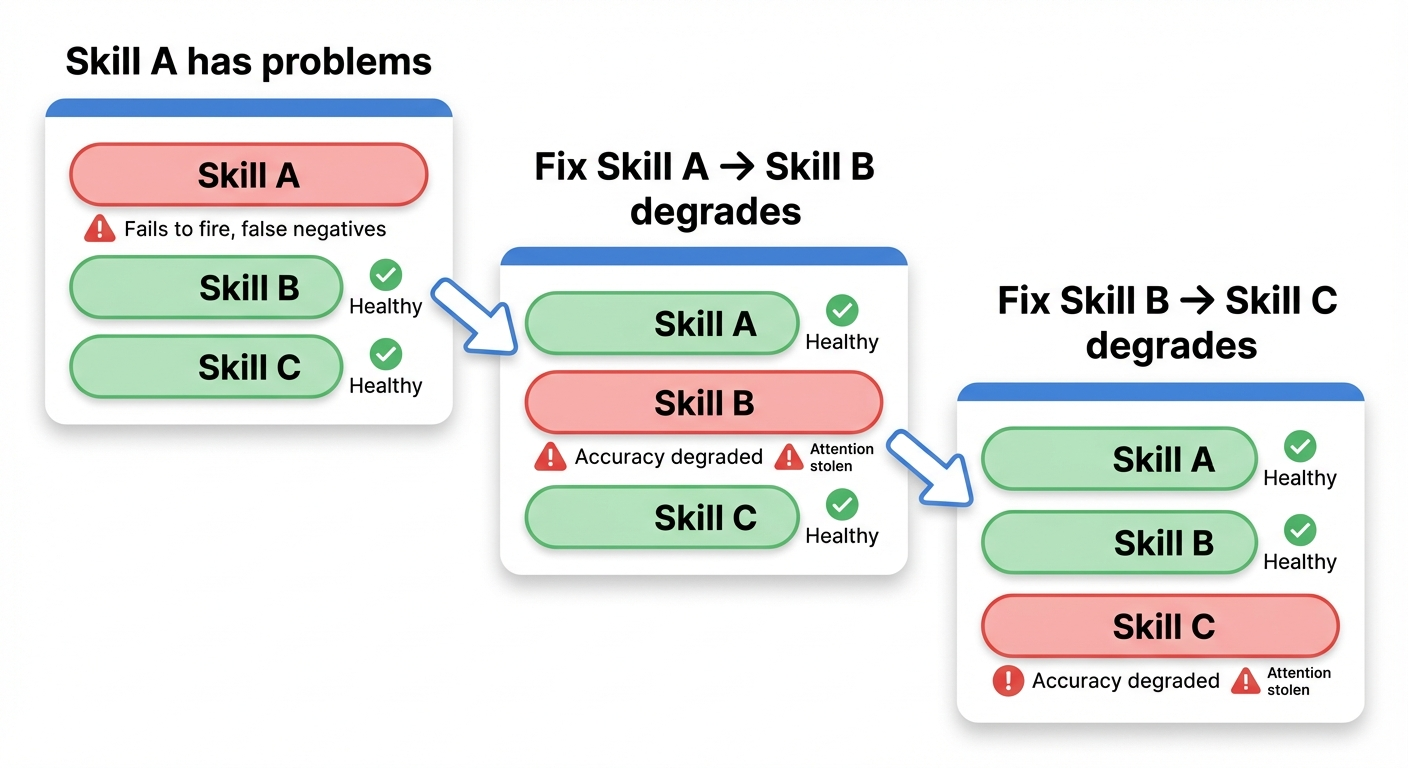
This isn't intuition, it's experimentally observed. Tool Preferences in Agentic LLMs are Unreliable shows that LLM tool selection is extremely fragile to the exact wording of descriptions. Even for functionally identical tools, adding "assertive cues" alone raises usage rates by more than 7x, and combining methods pushes it past 11x. In other words, if you make one skill's description pushier, neighbors get picked less. Description optimization is fundamentally a zero-sum contest.
skill-creator is excellent at polishing individual skills, but it doesn't handle this "set-level optimization". You need a mechanism that adjusts descriptions with awareness of inter-skill relationships across the whole portfolio.
That's the motivation for skill-auditor.
Designing skill-auditor
What it does
skill-auditor is a skill that analyzes real Claude Code session logs (transcripts) and automatically detects and reports on:
- Routing accuracy for each skill (did it fire correctly, misfire, or miss)
- Inter-skill relationships (orthogonal / adjacent / overlapping / nested)
- Attention Budget visualization (skills with high instruction density, skills with colliding trigger words)
- Coverage gaps (user intents that no existing skill covers)
- Concrete improvement patches (proposed description changes with diffs)
In the end it generates an HTML report and opens it in your browser.
Division of labor with skill-creator
| Aspect | skill-creator | skill-auditor |
|---|---|---|
| Timing | Pre-deployment (creation) | Post-deployment (operation) |
| Scope | Individual skill | The whole portfolio |
| Data | Synthetic test queries | Real session logs |
| Unit of optimization | A single description | A full skill set (with cascade checks) |
| Core question | "Is this skill good?" | "Do these skills work well together?" |
So: build a skill with skill-creator, polish it individually, then use skill-auditor to watch the health of the whole portfolio in production. As a CI/CD analogy, skill-creator is unit tests, skill-auditor is integration tests.
Architecture: a fusion pattern
In the previous post I wrote that "Sub-agent style and Skill Chain style aren't mutually exclusive, and fusion patterns are possible." skill-auditor is exactly that fusion pattern.
The overall flow is a sequential pipeline (Skill Chain-ish). Each phase depends on the previous phase's output, so it has to be sequential.
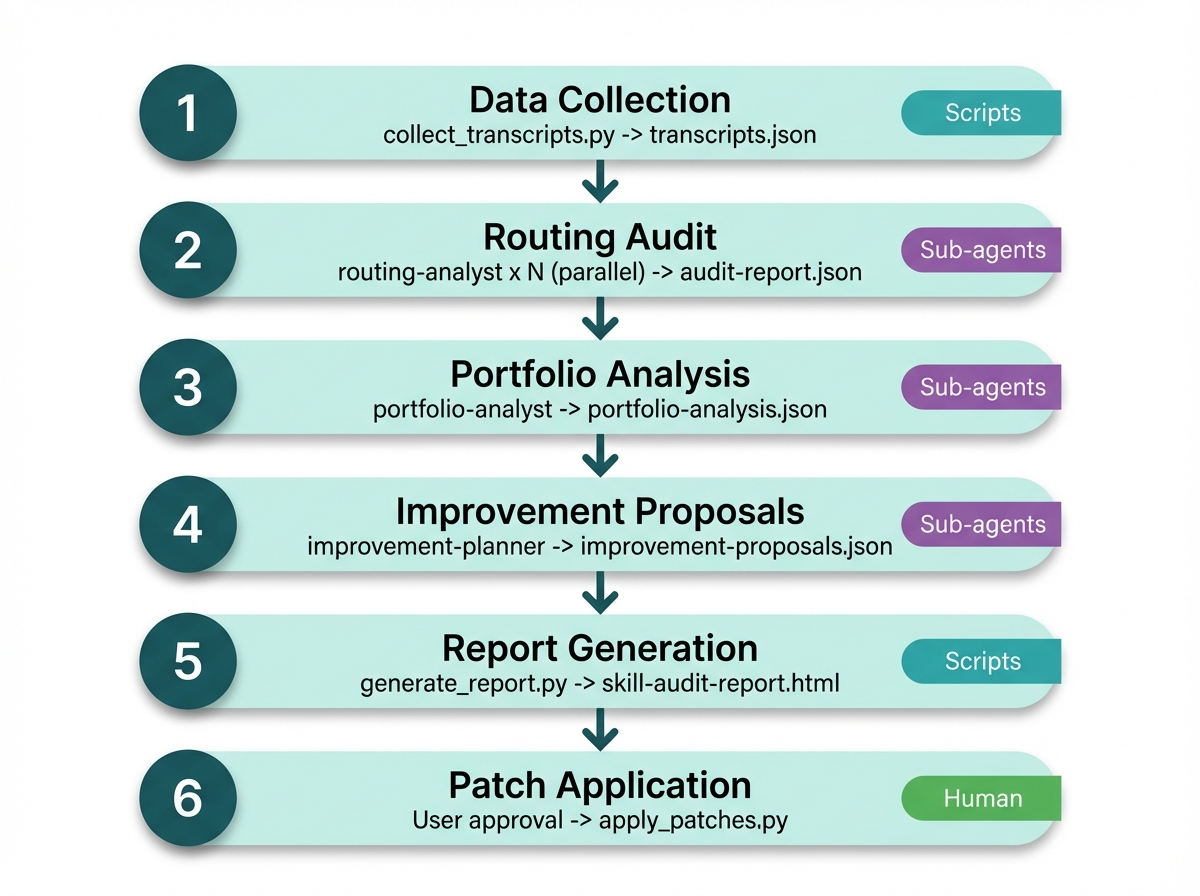
But Phase 2 runs N routing-analysis sub-agents in parallel on the same data (Sub-agent-ish). Phase 3 and 4 also delegate to specialized sub-agents.
Mapped to Anthropic's Building Effective Agents patterns, it looks like this:
| Anthropic pattern | Where it shows up in skill-auditor |
|---|---|
| Prompt Chaining | The Phase 1→2→3→4→5→6 sequential pipeline |
| Parallelization | The routing-analyst × N batching in Phase 2 |
| Orchestrator-Workers | SKILL.md as orchestrator, delegating to 3 kinds of workers |
The 3-layer split
The thing I cared about in the design was drawing a clear line between "what goes in scripts, what goes in sub-agents, what goes in the coordinator".
| Layer | Responsibility | Why |
|---|---|---|
| scripts/ (Python) | Transcript collection, token counting, HTML generation | Deterministic and needs to be exact. LLMs miscount |
| agents/ (Sub-agent) | Routing correctness judgments, relationship classification, cascade risk assessment | Judgment and reasoning. LLMs are good at this |
| SKILL.md (coordinator) | Data flow control, batch splitting, merging, dialog with the user | A thin orchestration layer that understands the whole flow |
The practices I learned from skill-creator, "push deterministic work into scripts" and "keep SKILL.md as a pure orchestrator", apply directly here.
Batch strategy for multi-project analysis
skill-auditor supports analysis across all projects. The wrinkle is that the visible skill set differs per project.
Global skills (~/.claude/skills/) are available in every session, but project-local skills (<project>/.claude/skills/) are only available in that project's sessions. Conflate them and you get false_negative over-detection.
So I use this batch strategy:
- Pool all sessions from projects that have no local skills into a single group (the same skill set is visible, so it's safe to mix)
- Group projects that share the same local skill set
- If batches exceed MAX_BATCHES (default 12), greedily merge by skill-set similarity
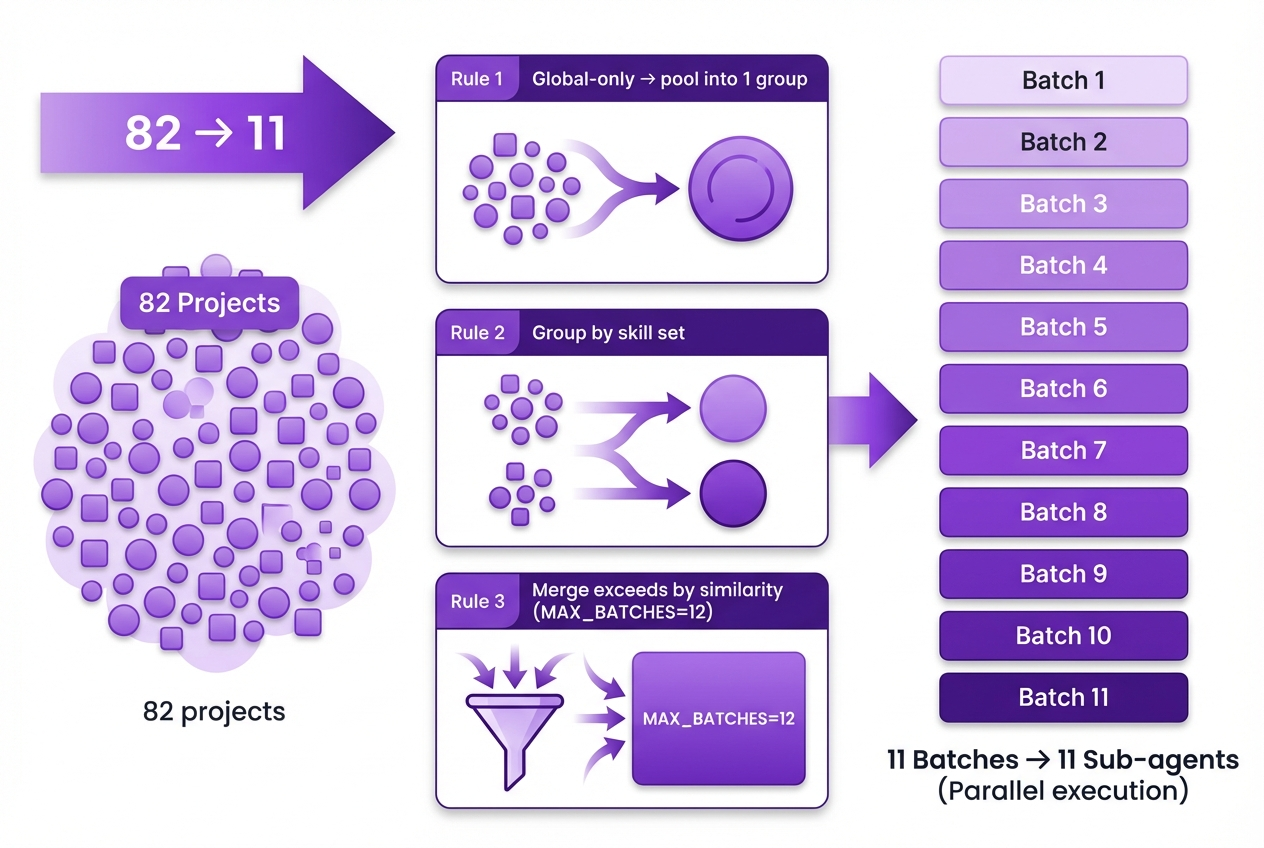
In my actual environment, 82 projects compressed into 11 batches, and 11 sub-agents ran in parallel. The reason MAX_BATCHES exists is to avoid launching too many sub-agents at once.
Judging routing correctness
There's no ground-truth label for "did the right skill fire". Users don't helpfully annotate their own intent.
So I use the LLM-as-a-Judge approach (using an LLM as the judge). Since the sub-agent reads the session context to judge, more precisely it's an Agent-as-a-Judge pattern. Anthropic's Demystifying evals for AI agents recommends this too.
For each user turn, the routing-analyst sub-agent produces one of these judgments:
| Judgment | Meaning |
|---|---|
| correct | The right skill fired correctly |
| false_negative | Should have fired but didn't |
| false_positive | Fired when it shouldn't have |
| confused | The wrong skill fired |
| no_skill_needed | No skill is relevant (most turns) |
| explicit_invocation | User called /skill-name explicitly (excluded from routing eval) |
| coverage_gap | Intent that no existing skill covers |
To keep the Agent-as-a-Judge accurate, I added a few safeguards:
- A structured rubric (agents/routing-analyst.md) spelling out the judgment criteria
- Each judgment carries a confidence (high / medium / low)
- One-off incidents are noise; only 2+ occurrences count as a signal
- false_negative judgments are conservative ("might be nice to have" doesn't count)
- Skills with
disable-model-invocation: trueare excluded since not firing is correct behavior - Claude Code's built-in commands (
/usage,/help, 30+ of them) aren't mistaken for skill calls
Patches with cascade checks
Every patch proposal from the improvement-planner sub-agent comes with a "cascade risk" assessment.
When it changes a skill's description, it checks whether the proposed keywords overlap with other skills' descriptions. If they do, it proposes a "coordinated fix" with both patches bundled together.
A direct answer to the whack-a-mole problem.
Parallels with Agent evaluation research
I've been walking through skill-auditor's design, but step back and it's the same problem Agent evaluation research is wrestling with.
Anthropic's Demystifying evals for AI agents puts the root difficulty this way: "The capabilities that make agents useful also make them harder to evaluate." Multi-turn agent behavior cascades errors, and frontier models find solutions the evaluator didn't imagine. That question of "how do you evaluate non-deterministic behavior" is precisely what skill-auditor faces when judging routing correctness from session logs.
Agent evaluation approaches can be organized into three generations:
| Generation | What's evaluated | Representative methods / benchmarks | Limits |
|---|---|---|---|
| Outcome-only | Correctness of the final answer | SWE-bench, WebArena | Doesn't look at "how you got to the answer". Can't tell inefficient reasoning from accidental correct answers |
| Trajectory-aware | The full behavioral trajectory | TRACE, τ-bench / τ²-bench | Can measure process quality, but scaling the evaluation itself is hard |
| Agent-as-a-Judge | Agents evaluating agents | Agent-as-a-Judge Survey, AgentRewardBench | Evaluator bias, reproducibility |
The TRACE paper proposes the concept of a "high-score illusion": even with a high final accuracy, the process might have been inefficient or the reasoning brittle. Mapped to skill-auditor's context, "the skill fired" alone doesn't tell you whether it fired in the right context for the right intent. That's why skill-auditor evaluates not just Outcome (fired or not) but Trajectory (routing judgments in the context of the whole session).
Also, Beyond Task Completion proposes an evaluation framework that goes beyond the binary of task completion. Even if the agent completed the task, if it violated policy or had side effects, you can't call that "success". skill-auditor's detection of false_positive (unnecessary firing) or confused (the wrong skill firing) is exactly this kind of "evaluation beyond task completion".
Placing skill-auditor's design choices in this evaluation-paradigm context gives:
| Agent evaluation challenge | skill-auditor's approach |
|---|---|
| No ground truth labels (unsupervised) | Agent-as-a-Judge judges from context, with a structured rubric and confidence labels |
| Non-deterministic behavior paths | Accept that the firing skill can vary for the same query, and treat patterns (2+ occurrences) as signals |
| Evaluator bias | Be conservative on false_negative judgments — "would be nice to have" doesn't count |
| Process vs outcome | Evaluate both firing (Outcome) and routing correctness in session context (Trajectory) |
| Scalability | Batch splitting + parallel sub-agents to process 472 sessions / 17,851 turns |
As the Anthropic evals article says, "You won't know if your graders are working well unless you read the transcripts and grades from many trials": in the end, reading transcripts is the starting point. skill-auditor automates the "reading transcripts and spotting patterns" human work via the Agent-as-a-Judge pattern.
Even so, even on the frontier of agent development, this "humans grinding through transcripts and actual outputs" process hasn't been fully automated.
In a recently published LangChain and Manus webinar (Context Engineering for AI Agents with LangChain and Manus), Manus co-founder Peak also had some telling things to say about the difficulty of evaluating Agents. He pointed out the problem that scoring well on public benchmarks (like Gaia) doesn't match actual user preferences, and revealed that for final quality assurance they "hire a lot of human interns to manually evaluate actual outputs (websites, data visualizations) and logs":
"it's very hard to design a good reward model that knows whether the output is visually appealing like it it's about the taste. Yeah. So we still rely on a lot of a lot a lot." — Yichao "Peak" Ji (Manus)
The more complex an LLM agent gets, the harder it is to close the evaluation loop with automation alone. In the end, qualitative human review is indispensable. That's why skill-auditor lands where it does: scale the "mechanically summarizable" parts (routing correctness, conflict mapping) via Agent-as-a-Judge, while also generating an HTML report with patch Diff views and a Competition Matrix that a human can scan to make the final call.
Actually using it
Running it
Launch it with /skill-auditor, choose a report language (Japanese) and analysis scope (all projects), and it takes you from data collection through to report generation automatically. 11 routing-analysis sub-agents run in parallel, and the whole thing finished in about 15 minutes.
Here's what the run on my environment looked like:
- Scope: 472 sessions, 17,851 user turns (14 days, all projects)
- Detected skills: 32 definitions (20 global + 12 project-local)
- Attention Budget: 2,151 tokens total
- Turns where a skill fired: 41
The report
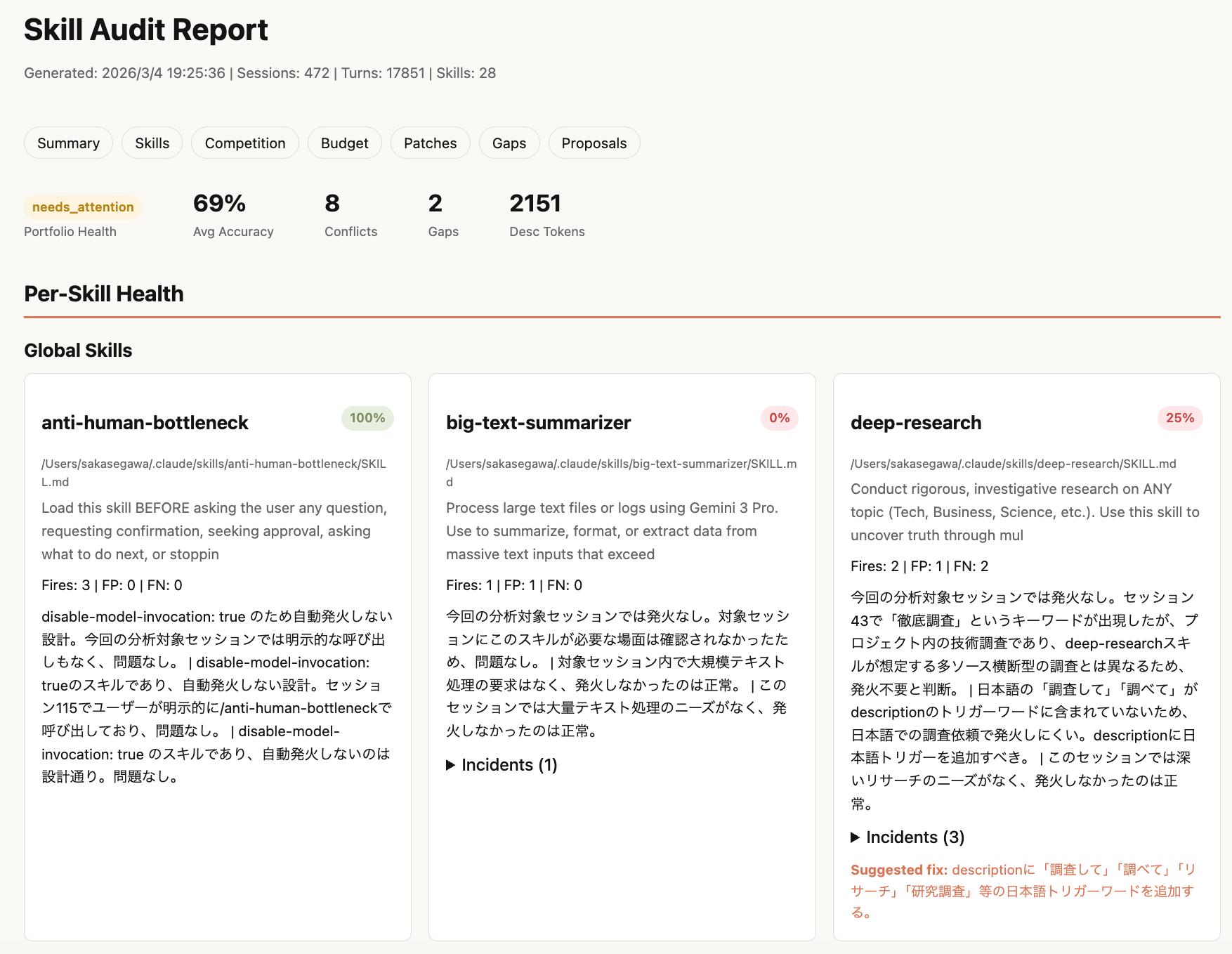
An HTML report is generated and opened in the browser. It packages together the summary, Per-Skill Health cards (split into global / per-project), Competition Matrix, Attention Budget, patch diff views, coverage gaps, and so on.
Each skill card shows the file path, so you can instantly tell which directory a skill lives in, including where symlinks point.
Problems it found
Average routing accuracy for the whole portfolio came in at 0.685. A few notable findings:
remotion-best-practices: description too short (accuracy 0.2)
The description was just "Best practices for Remotion - Video creation in React" at 10 tokens, and 4 false_negatives occurred. Even when the user said "I want to build videos with Remotion", it didn't fire, and I even found cases where I was manually pasting in the skill's content.
The proposed patch expands it to about 82 tokens by adding Japanese trigger words and Remotion-specific API keywords (Composition, spring, useCurrentFrame, etc.).
deep-research: "ANY topic" is too broad (accuracy 0.25)
The description "Conduct rigorous, investigative research on ANY topic" had "ANY topic" too broad, so it would misfire on file checks or directory-structure questions during coding work. Out of 2 firings, 1 was a misfire, with 2 additional false_negatives.
The patch removes "ANY topic" and narrows the scope to "exploratory investigative research using web search and primary sources", plus adds exclusion conditions.
skill-creator: misfires in skill-dev contexts (accuracy 0.333)
The description doesn't distinguish "talking about skills" from "wanting to build a skill", and 2 of 4 firings were misfires. The boundary with linear-tasks is also fuzzy, with confusion on task-management utterances.
Competition Matrix reveals the need for coordinated fixes

8 competing pairs were detected. A few that stand out:
- remotion-best-practices ↔ remotion-promo-video-factory: nested. best-practices covers all Remotion code, and promo-video-factory is a subset. The boundary needs to be "best-practices fires first, and only requests specific to promo videos route to factory"
- linear-tasks ↔ skill-creator: adjacent. Skill-dev tooling misfires on Linear task utterances
- repo-analyzer ↔ skill-creator: adjacent. The boundary between repo analysis and skill creation is fuzzy
Attention Budget
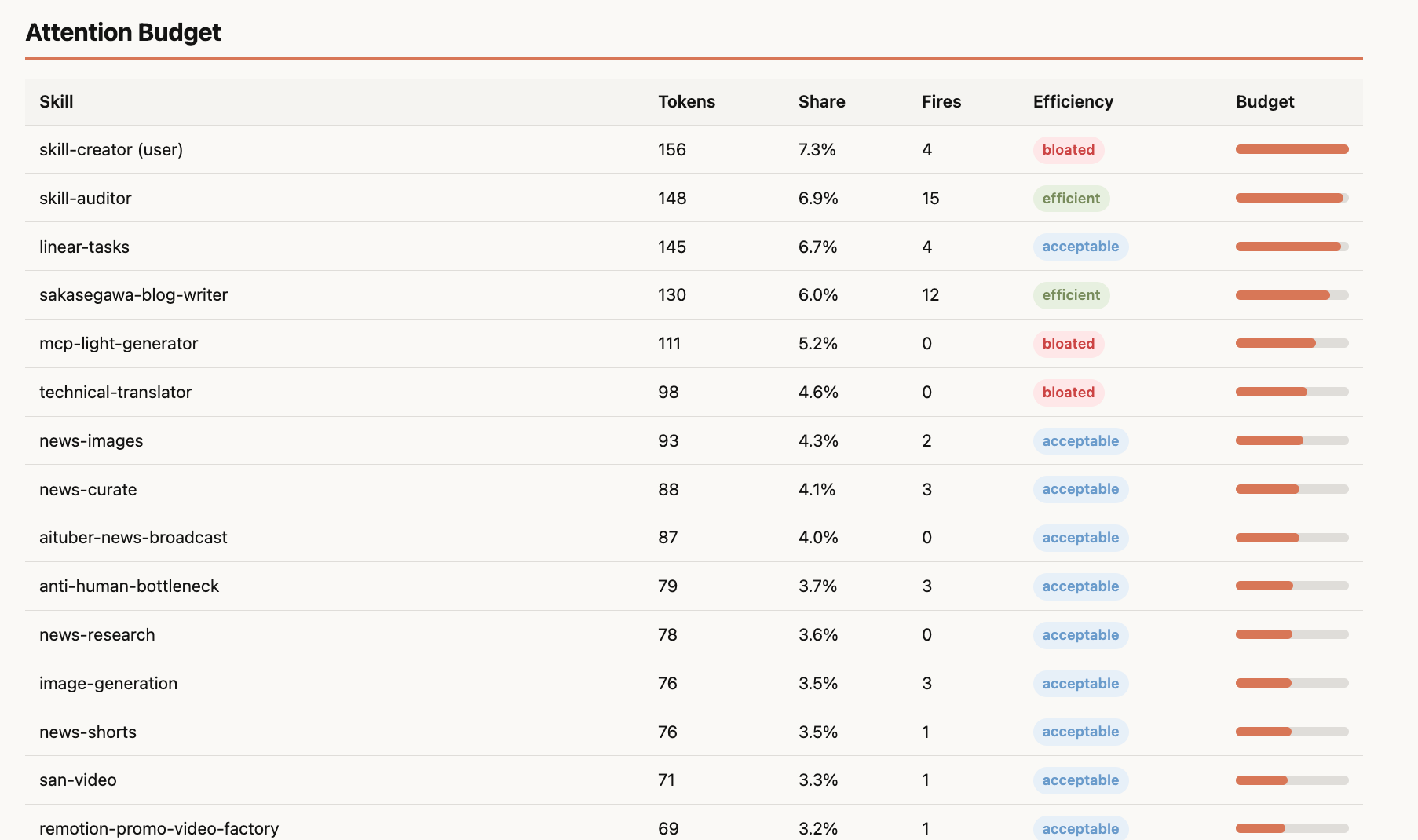
Token consumption for all 32 skills is visualized. skill-creator (156 tokens, 7.3%), skill-auditor (148 tokens, 6.9%), and linear-tasks (145 tokens, 6.7%) top the list.
As mentioned earlier, attention competition depends on directive density more than raw token count. skill-auditor has 148 tokens with 15 firings at 100% accuracy, so the token count isn't a problem. Meanwhile mcp-light-generator (111 tokens) and technical-translator (98 tokens) had 0 firings, so their directives are just floating there.
Improvement Patches

10 patches were proposed. 6 high, 2 medium, 2 low priority.
The patches for remotion-best-practices and remotion-promo-video-factory are proposed as coordinated fixes: broaden best-practices' firing scope while making its boundary with promo-video-factory explicit. Applying only one of them can backfire, so they're recommended as a pair.
Coverage Gaps & New Skill Proposals

Coverage gaps dropped to 2 (from 22 in the previous run. That time a symlink issue was hiding skills from the scan).
As a new skill proposal, it suggested "notion-linear-sync" for cross-syncing Notion pages and Linear tasks.
File layout of skill-auditor
For reference, here's the actual file layout.
skills/skill-auditor/
├── SKILL.md # Coordinator (~340 lines)
├── agents/
│ ├── routing-analyst.md # Expert on routing correctness
│ ├── portfolio-analyst.md # Attention Budget + Competition Matrix analysis
│ └── improvement-planner.md # Patch proposals with cascade checks
├── schemas/
│ └── schemas.md # All JSON schema definitions (7 types)
├── scripts/
│ ├── collect_transcripts.py # Collect and parse session logs
│ ├── collect_skills.py # Collect skill definitions + token counting
│ ├── generate_report.py # HTML report generation
│ └── apply_patches.py # Patch application
├── assets/
│ └── report_template.html # Report template
└── references/
├── methodology.md # Theoretical background (IR analogy, LLM-as-Judge, etc.)
└── architecture.md # Rationale for architectural choices
The practices from the previous post show up here:
- SKILL.md stays a thin flow controller (~340 lines)
- Specialist work is isolated in agents/ (routing-analyst, portfolio-analyst, improvement-planner)
- Deterministic work is pushed into scripts/ (collection, counting, HTML generation)
- Schema contracts live in schemas/ (7 JSON schemas)
- Deep background lives in references/ (Progressive Disclosure)
Each run goes into a timestamped sub-directory (e.g. 2026-03-04T19-05-31/), so running multiple times doesn't overwrite intermediate outputs. Only health-history.json is shared across runs, so you can track accuracy over time.
Summary
- skill-creator is great for polishing skills individually, but it doesn't systematically control inter-skill attention competition (the portfolio problem)
- skill-auditor audits portfolio-wide routing accuracy from real session logs and proposes patches with cascade checks
- This approach is the same class of problem as Agent evaluation research (Outcome-only → Trajectory-aware → Agent-as-a-Judge). Skill routing audit is a form of the Agent evaluation problem
- On a real environment (32 skills, 472 sessions), it found average accuracy 0.685, proposed 10 patches, and detected 8 competing pairs
References
Related posts
Official docs
- The Complete Guide to Building Skills for Claude
- Equipping Agents for the Real World with Agent Skills
- Best Practices
- Building Effective Agents
- Demystifying evals for AI agents
Instruction Following / Tool Selection
- How Many Instructions Can LLMs Follow at Once? — quantitative evaluation of instruction density and LLM compliance
- Tool Preferences in Agentic LLMs are Unreliable — demonstrates how fragile tool selection is to description edits
Agent Evaluation / Context Engineering
- Context Engineering for AI Agents with LangChain and Manus — Manus's Peak on the messy reality of Agent evaluation
Papers on Agent evaluation
- TRACE: Trajectory-Aware Comprehensive Evaluation for Deep Research Agents — trajectory-aware evaluation that goes beyond Outcome-only "high-score illusion"
- AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories — systematically tests LLM-as-Judge accuracy
- Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems — multi-dimensional evaluation beyond task completion
- τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains — real-world domain Agent dialogue benchmark
- A Survey on Agent-as-a-Judge — survey of the evolution from LLM-as-Judge to Agent-as-a-Judge
Related repositories
- anthropics/skills/skill-creator — Anthropic's official meta-skill
- nyosegawa/skills/skill-auditor — the skill-auditor introduced in this post